I loaded up this title with buzzwords. The basic idea is that IM systems shouldn t have to only use the Internet. Why not let them be carried across LoRa radios, USB sticks, local Wifi networks, and yes, the Internet? I ll first discuss how, and then why.
How do set it up
I ve talked about most of the pieces here already:
Delta Chat, which is an IM app that uses mail servers (SMTP and IMAP) as transport, and OpenPGPencryption for security.
Yggdrasil, which forms an auto-mesh network over things like ad-hoc wifi. It s not asynchronous itself, but its properties may be used to build an asyncrhonous email network email itself can be asynchronous across any carrier. Others such as Tor could also be used.
And various other physical carriers such as LoRa and XBee SX radios.
Email servers. For instance, there are existing instructions for running Postfixor Exim over NNCP. These can be easily adapted to run across something like Filespooler instead. These can be run locally on a laptop, or, with a tool such as Termux, on Android.
So, putting this together:
All Delta Chat needs is access to a SMTP and IMAP server. This server could easily reside on localhost.
Existing email servers support transport of email using non-IP transports, including batch transports that can easily store it in files.
These batches can be easily carried by NNCP, Syncthing, Filespooler, etc. Or, if the connectivity is good enough, via traditional networking using Yggdrasil.
Side note: Both NNCP and email servers support various routing arrangements, and can easily use intermediary routing nodes. Syncthing can also mesh. NNCP supports asynchronous multicast, letting your messages opportunistically find the best way to their destination.
OK, so why would you do it?
You might be thinking, doesn t asynchronous mean slow? Well, not necessarily. Asynchronous means reliability is more important than speed ; that is, slow (even to the point of weeks) is acceptable, but not required. NNCP and Syncthing, for instance, can easily deliver within a couple of seconds.
But let s step back a bit. Let s say you re hiking in the wilderness in an area with no connectivity. You get back to your group at a campsite at the end of the day, and have taken some photos of the forest and sent them to some friends. Some of those friends are at the campsite; when you get within signal range, they get your messages right away. Some of those friends are in another country. So one person from your group drives into town and sits at a coffee shop for a few minutes, connected to their wifi. All the messages from everyone in the group go out, all the messages from outside the group come in. Then they go back to camp and the devices exchange messages.
Pretty slick, eh?
Note: this article also has a more permanent home on my website, where it may be periodically updated.
Welcome to yet another report from the Reproducible Builds project, this time for November 2022. In all of these reports (which we have been publishing regularly since May 2015) we attempt to outline the most important things that we have been up to over the past month. As always, if you interested in contributing to the project, please visit our Contribute page on our website.
Reproducible Builds Summit 2022
Following-up from last month s report about our recent summit in Venice, Italy, a comprehensive report from the meeting has not been finalised yet watch this space!
As a very small preview, however, we can link to several issues that were filed about the website during the summit (#38, #39, #40, #41, #42, #43, etc.) and collectively learned about Software Bill of Materials (SBOM) s and how .buildinfo files can be seen/used as SBOMs. And, no less importantly, the Reproducible Builds t-shirt design has been updated
Reproducible Builds at European Cyber Week 2022
During the European Cyber Week 2022, a Capture The Flag (CTF) cybersecurity challenge was created by Fr d ric Pierret on the subject of Reproducible Builds. The challenge consisted in a pedagogical sense based on how to make a software release reproducible. To progress through the challenge issues that affect the reproducibility of build (such as build path, timestamps, file ordering, etc.) were to be fixed in steps in order to get the final flag in order to win the challenge.
At the end of the competition, five people succeeded in solving the challenge, all of whom were awarded with a shirt. Fr d ric Pierret intends to create similar challenge in the form of a how to in the Reproducible Builds documentation, but two of the 2022 winners are shown here:
[ ] industry application of R-Bs appears limited, and we seek to understand whether awareness is low or if significant technical and business reasons prevent wider adoption.
This is achieved through interviews with software practitioners and business managers, and touches on both the business and technical reasons supporting the adoption (or not) of Reproducible Builds. The article also begins with an excellent explanation and literature review, and even introduces a new helpful analogy for reproducible builds:
[Users are] able to perform a bitwise comparison of the two binaries to verify that they are identical and that the distributed binary is indeed built from the source code in the way the provider claims. Applied in this manner, R-Bs function as a canary, a mechanism that indicates when something might be wrong, and offer an improvement in security over running unverified binaries on computer systems.
The full paper is available to download on an open access basis.
Elsewhere in academia, Beatriz Michelson Reichert and Rafael R. Obelheiro have published a paper proposing a systematic threat model for a generic software development pipeline identifying possible mitigations for each threat (PDF). Under the Tampering rubric of their paper, various attacks against Continuous Integration (CI) processes:
An attacker may insert a backdoor into a CI or build tool and thus introduce vulnerabilities into the software (resulting in an improper build). To avoid this threat, it is the developer s responsibility to take due care when making use of third-party build tools. Tampered compilers can be mitigated using diversity, as in the diverse double compiling (DDC) technique. Reproducible builds, a recent research topic, can also provide mitigation for this problem. (PDF)
Misc news
A change was proposed for the Go programming language to enable reproducible builds when Link Time Optimisation (LTO) is enabled. As mentioned in the changelog, Morten Linderud s patch fixes two issues when the linker used in conjunction with the -flto option: the first involves solving an issue related to seeded random numbers; and the second involved the binary embedding the current working directory in compressed sections of the LTO object. Both of these issues made the build unreproducible.
Our monthly IRC meeting was held on November 29th 2022. Our next meeting will be on January 31st 2023; we ll skip the meeting in December due to the proximity to Christmas, etc.
Vagrant Cascadian posed an interesting question regarding the difference between test builds vs rebuilds (or verification rebuilds ). As Vagrant poses in their message, they re both useful for slightly different purposes, and it might be good to clarify the distinction [ ].
Debian & other Linux distributions
Over 50 reviews of Debian packages were added this month, another 48 were updated and almost 30 were removed, all of which adds to our knowledge about identified issues. Two new issue types were added as well. [][].
Vagrant Cascadian announced on our mailing list another online sprint to help clear the huge backlog of reproducible builds patches submitted by performing NMUs (Non-Maintainer Uploads). The first such sprint took place on September 22nd, but others were held on October 6th and October 20th. There were two additional sprints that occurred in November, however, which resulted in the following progress:
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 226 and 227 to Debian:
Support both python3-progressbar and python3-progressbar2, two modules providing the progressbar Python module. []
Don t run Python decompiling tests on Python bytecode that file(1) cannot detect yet and Python 3.11 cannot unmarshal. (#1024335)
Don t attempt to attach text-only differences notice if there are no differences to begin with. (#1024171)
Make sure we recommend apksigcopier. []
Tidy generation of os_list. []
Make the code clearer around generating the Debian substvars . []
Use our assert_diff helper in test_lzip.py. []
Drop other copyright notices from lzip.py and test_lzip.py. []
In addition to this, Christopher Baines added lzip support [], and FC Stegerman added an optimisation whereby we don t run apktool if no differences are detected before the signing block [].
A significant number of changes were made to the Reproducible Builds website and documentation this month, including Chris Lamb ensuring the openEuler logo is correctly visible with a white background [], FC Stegerman de-duplicated by email address to avoid listing some contributors twice [], Herv Boutemy added Apache Maven to the list of affiliated projects [] and boyska updated our Contribute page to remark that the Reproducible Builds presence on salsa.debian.org is not just the Git repository but is also for creating issues [][]. In addition to all this, however, Holger Levsen made the following changes:
Add a number of existing publications [][] and update metadata for some existing publications as well [].
Add the Warpforge build tool as a participating project of the summit. []
Clarify in the footer that we welcome patches to the website repository. []
Testing framework
The Reproducible Builds project operates a comprehensive testing framework at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In October, the following changes were made by Holger Levsen:
Improve the generation of meta package sets (used in grouping packages for reporting/statistical purposes) to treat Debian bookworm as equivalent to Debian unstable in this specific case []
and to parse the list of packages used in the Debian cloud images [][][].
Temporarily allow Frederic to ssh(1) into our snapshot server as the jenkins user. []
Keep some reproducible jobs Jenkins logs much longer [] (later reverted).
Improve the node health checks to detect failures to update the Debian cloud image package set [][] and to improve prioritisation of some kernel warnings [].
Always echo any IRC output to Jenkins output as well. []
Deal gracefully with problems related to processing the cloud image package set. []
Finally, Roland Clobus continued his work on testing Live Debian images, including adding support for specifying the origin of the Debian installer [] and to warn when the image has unmet dependencies in the package list (e.g. due to a transition) [].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. You can get in touch with us via:
TL;DR
Never trust show commit changes diff on Cisco IOS XR.
Cisco IOS XR is the operating system running for the Cisco ASR, NCS, and
8000 routers. Compared to Cisco IOS, it features a candidate
configuration and a running configuration. In configuration mode, you can
modify the first one and issue the commit command to apply it to the running
configuration.1 This is a common concept for many NOS.
Before committing the candidate configuration to the running configuration, you
may want to check the changes that have accumulated until now. That s where the
show commit changes diff command2 comes up. Its goal is to show the
difference between the running configuration (show running-configuration) and
the candidate configuration (show configuration merge). How hard can it be?
Let s put an interface down on IOS XR 7.6.2 (released in August 2022):
The + sign before interface HundredGigE0/1/0/1 makes it look like you did
create a new interface. Maybe there was a typo? No, the diff is just broken. If
you look at the candidate configuration, everything is like you expect:
RP/0/RP0/CPU0:router(config)#show configuration merge int Hu0/1/0/1
Wed Nov 23 11:08:43.360 CETinterface HundredGigE0/1/0/1 description PNI: (some description) bundle id 4000 mode active lldp receive disable transmit disable ! shutdown load-interval 30
Here is a more problematic example on IOS XR 7.2.2 (released in January 2021).
We want to unconfigure three interfaces:
RP/0/RP0/CPU0:router(config)#no int GigabitEthernet 0/0/0/5
RP/0/RP0/CPU0:router(config)#int TenGigE 0/0/0/5 shut
RP/0/RP0/CPU0:router(config)#no int TenGigE 0/0/0/28
RP/0/RP0/CPU0:router(config)#int TenGigE 0/0/0/28 shut
RP/0/RP0/CPU0:router(config)#no int TenGigE 0/0/0/29
RP/0/RP0/CPU0:router(config)#int TenGigE 0/0/0/29 shut
RP/0/RP0/CPU0:router(config)#show commit changes diff
Mon Nov 7 15:07:22.990 CETBuilding configuration...!! IOS XR Configuration 7.2.2- interface GigabitEthernet0/0/0/5- shutdown !+ interface TenGigE0/0/0/5+ shutdown ! interface TenGigE0/0/0/28- description Trunk (some description)- bundle id 2 mode active !end
The two first commands are correctly represented by the first two chunks of the
diff: we remove GigabitEthernet0/0/0/5 and create TenGigE0/0/0/5. The two
next commands are also correctly represented by the last chunk of the diff.
TenGigE0/0/0/28 was already shut down, so it is expected that only
description and bundle id are removed. However, the diff command forgets
about the modifications for TenGigE0/0/0/29. The diff should include a chunk
similar to the last one.
RP/0/RP0/CPU0:router(config)#show run int TenGigE 0/0/0/29
Mon Nov 7 15:07:43.571 CETinterface TenGigE0/0/0/29 description Trunk to other router bundle id 2 mode active shutdown!RP/0/RP0/CPU0:router(config)#show configuration merge int TenGigE 0/0/0/29
Mon Nov 7 15:07:53.584 CETinterface TenGigE0/0/0/29 shutdown!
How can the diff be correct for TenGigE0/0/0/28 but incorrect for
TenGigE0/0/0/29 while they have the same configuration? How can you trust the
diff command if it forgets part of the configuration?
Do you remember the last time you ran an Ansible playbook and discovered the
whole router ospf block disappeared without a warning? If you use automation
tools, you should check how the diff is assembled. Automation tools should build
it from the result of show running-config and show configuration merge. This
is what NAPALM does. This is not what cisco.iosxr
collection for Ansible does.
The problem is not limited to the interface directives. You can get similar
issues for other parts of the configuration. For example, here is what we get
when removing inactive BGP neighbors on IOS XR 7.2.2:
The only correct chunk is for neighbor 217.29.66.112. All the others are missing
some of the removed lines. 217.29.67.15 is even missing all of them. How bad is
the code providing such a diff?
I could go all day with examples such as these. Cisco TAC is happy to open a
case in DDTS, their bug tracker, to fix specific occurrences of this
bug.3 However, I fail to understand why the XR team is not just
providing the diff between show run and show configuration merge. The output
would always be correct!
IOS XR has several limitations. The most inconvenient one is the
inability to change the AS number in the router bgp directive. Such a
limitation is a great pain for both operations and automation.
This command could have been just show commit, as show commit
changes diff is the only valid command you can execute from this point.
Starting from IOS XR 7.5.1, show commit changes diff precise is also a
valid command. However, I have failed to find any documentation about it and
it seems to provide the same output as show commit changes diff. That s
how clunky IOS XR can be.
See CSCwa26251 as an example of a fix for something I reported
earlier this year. You need a valid Cisco support contract to be able to see
its content.
History, Setup
So for quite some time I have a QNAP TS-873x here, equipped with 8
Western Digital Red 10 TB disks, plus 2 WD Blue 500G M2 SSDs. The QNAP
itself has an AMD Embedded R-Series RX-421MD with 4 cores and was
equipped with 48G RAM.
Initially I had been quite happy, the system is nice. It was fast, it
was easy to get to run and the setup of things I wanted was simple
enough. All in a web interface that tries to imitate a kind of
workstation feeling and also tries to hide that it is actually a
webinterface.
Natually with that amount of disks I had a RAID6 for the disks, plus
RAID1 for the SSDs. And then configured as a big storage pool with the
RAID1 as cache. Below the hood QNAP uses MDADM Raid and LVM (if you
want, with thin provisioning), in some form of emdedded linux. The
interface allows for regular snapshots of your storage with flexible
enough schedules to create them, so it all appears pretty good.
QNAP slow
Fast forward some time and it gets annoying. First off you really
should have regular raid resyncs scheduled, and while you can set
priorities on them and have them low priority, they make the whole
system feel very sluggish, quite annoying. And sure, power failure
(rare, but can happen) means another full resync run. Also, it appears
all of the snapshots are always mounted to some
/mnt/snapshot/something place (df on the system gets quite unusable).
Second, the reboot times. QNAP seems to be affected by the more
features, fuck performance virus, and bloat their OS with more and
more features while completly ignoring the performance. Everytime they
do an upgrade it feels worse. Lately reboot times went up to 10 to
15 minutes - and then it still hadn t started the virtual machines /
docker containers one might run on. Another 5 to 10 minutes for those.
Opening the file explorer - ages on calculating what to show. Trying
to get the storage setup shown? Go get a coffee, but please fetch the
beans directly from the plantation, or you are too fast.
Annoying it was. And no, no broken disks or fan or anything, it all
checks out fine.
Replace QNAPs QTS system
So I started looking around what to do. More RAM may help a little
bit, but I already had 48G, the system itself appears to only do 64G
maximum, so not much chance of it helping enough. Hardware is all fine
and working, so software needs to be changed. Sounds hard, but turns
out, it is not.
TrueNAS
And I found that multiple people replaced the QNAPs own system with a
TrueNAS installation and generally had been happy. Looking further I
found that TrueNAS has a variant called Scale - which is based on
Debian. Doubly good, that, so I went off checking what I may need for
it.
Requirements
Heck, that was a step back. To install TrueNAS you need an HDMI out
and a disk to put it on. The one that QTS uses is too small, so no
option.
QNAPs original internal
USB drive, DOM
So either use one of the SSDs that played cache (and
should do so again in TrueNAS, or get the QNAP original replaced.
HDMI out is simple, get a cheap card and put it into one of the two
PCIe-4x slots, done. The disk thing looked more complicated, as QNAP
uses some internal usb stick thing . Turns out it is just a USB
stick that has an 8+1pin connector. Couldn t find anything nice as
replacement, but hey, there are 9-pin to USB-A adapters.
a 9pin to USB A adapter
With that adapter, one can take some random M2 SSD and an M2-to-USB
case, plus some cabling, and voila, we have a nice system disk.
9pin adapter to USB-A connected with some
more cable
Obviously there isn t a good place to put this SSD case and cable, but the
QNAP case is large enough to find space and use some cable ties to store it
safely. Space enough to get the cable from the side, where the
mainboard is to the place I mounted it, so all fine.
Mounted SSD in its external case
The next best M2 SSD was a Western Digital Red with 500G - and while
this is WAY too much for TrueNAS, it works. And hey, only using a tiny
fraction? Oh so much more cells available internally to use when
others break. Or something
Together with the Asus card mounted I was able to install TrueNAS.
Which is simple, their installer is easy enough to follow, just make
sure to select the right disk to put it on.
Preserving data during the move
Switching from QNAP QTS to TrueNAS Scale means changing from MDADM
Raid with LVM and ext4 on top to ZFS and as such all data on it gets
erased. So a backup first is helpful, and I got myself two external
Seagate USB Disks of 6TB each - enough for the data I wanted to keep.
Copying things all over took ages, especially as the QNAP backup
thingie sucks, it was breaking quite often. Also, for some reason I
did not investigate, the performance of it was real bad. It started at
a maximum of 50MB/s, but the last terabyte of data was copied
at MUCH less than that, and so it took much longer than I anticipated.
Copying back was slow too, but much less so. Of course reading things
usually is faster than writing, with it going around 100MB/s most of
the time, which is quite a bit more - still not what USB3 can actually
do, but I guess the AMD chip doesn t want to go that fast.
TrueNAS experience
The installation went mostly smooth, the only real trouble had been on
my side. Turns out that a bad network cable does NOT help the network
setup, who would have thought. Other than that it is the usual set of
questions you would expect, a reboot, and then some webinterface.
And here the differences start. The whole system boots up much faster.
Not even a third of the time compared to QTS.
One important thing: As TrueNAS scale is Debian based, and hence a
linux kernel, it automatically detects and assembles the old RAID
arrays that QTS put on. Which TrueNAS can do nothing with, so it helps
to manually stop them and wipe the disks.
Afterwards I put ZFS on the disks, with a similar setup to what I had
before. The spinning rust are the data disks in a RAIDZ2 setup, the
two SSDs are added as cache devices. Unlike MDADM, ZFS does not have a
long sync process. Also unlike the MDADM/LVM/EXT4 setup from before,
ZFS works different. It manages the raid thing but it also does the
volume and filesystem parts. Quite different handling, and I m still
getting used to it, so no, I won t write some ZFS introduction now.
Features
The two systems can not be compared completly, they are having a
pretty different target audience. QNAP is more for the user that wants
some network storage that offers a ton of extra features easily
available via a clickable interface. While TrueNAS appears more
oriented to people that want a fast but reliable storage system.
TrueNAS does not offer all the extra bloat the QNAP delivers. Still,
you have the ability to run virtual machines and it seems it comes
with Rancher, so some kubernetes/container ability is there. It lacks
essential features like assigning PCI devices to virtual machines, so
is not useful right now, but I assume that will come in a future
version.
I am still exploring it all, but I like what I have right now. Still
rebuilding my setup to have all shares exported and used again, but
the most important are working already.
I started migrating my graphical workstations to Wayland, specifically
migrating from i3 to Sway. This is mostly to address serious graphics
bugs in the latest Framwork
laptop, but also something I
felt was inevitable.
The current status is that I've been able to convert my i3
configuration to Sway, and adapt my systemd startup sequence to the
new environment. Screen sharing only works with Pipewire, so I also
did that migration, which basically requires an upgrade to Debian
bookworm to get a nice enough Pipewire release.
I'm testing Wayland on my laptop, but I'm not using it as a daily
driver because I first need to upgrade to Debian bookworm on my main
workstation.
Most irritants have been solved one way or the other. My main problem
with Wayland right now is that I spent a frigging week doing the
conversion: it's exciting and new, but it basically sucked the life
out of all my other projects and it's distracting, and I want it to
stop.
The rest of this page documents why I made the switch, how it
happened, and what's left to do. Hopefully it will keep you from
spending as much time as I did in fixing this.
TL;DR: Wayland is mostly ready. Main blockers you might find are
that you need to do manual configurations, DisplayLink (multiple
monitors on a single cable) doesn't work in Sway, HDR and color
management are still in development.
I had to install the following packages:
And did some of tweaks in my $HOME, mostly dealing with my esoteric
systemd startup sequence, which you won't have to deal with if you are
not a fan.
Why switch?
I originally held back from migrating to Wayland: it seemed like a
complicated endeavor hardly worth the cost. It also didn't seem
actually ready.
But after reading this blurb on LWN, I decided to at least
document the situation here. The actual quote that convinced me it
might be worth it was:
It s amazing. I have never experienced gaming on Linux that looked
this smooth in my life.
... I'm not a gamer, but I docare about
latency. The longer version is
worth a read as well.
The point here is not to bash one side or the other, or even do a
thorough comparison. I start with the premise that Xorg is likely
going away in the future and that I will need to adapt some day. In
fact, the last major Xorg release (21.1, October 2021) is rumored
to be the last ("just like the previous release...", that said,
minor releases are still coming out, e.g. 21.1.4). Indeed, it
seems even core Xorg people have moved on to developing Wayland, or at
least Xwayland, which was spun off it its own source tree.
X, or at least Xorg, in in maintenance mode and has been for
years. Granted, the X Window System is getting close to forty
years old at this point: it got us amazingly far for something that
was designed around the time the firstgraphical
interface. Since Mac and (especially?) Windows released theirs,
they have rebuilt their graphical backends numerous times, but UNIX
derivatives have stuck on Xorg this entire time, which is a testament
to the design and reliability of X. (Or our incapacity at developing
meaningful architectural change across the entire ecosystem, take your
pick I guess.)
What pushed me over the edge is that I had some pretty bad driver
crashes with Xorg while screen sharing under Firefox, in Debian
bookworm (around November 2022). The symptom would be that the UI
would completely crash, reverting to a text-only console, while
Firefox would keep running, audio and everything still
working. People could still see my screen, but I couldn't, of course,
let alone interact with it. All processes still running, including
Xorg.
(And no, sorry, I haven't reported that bug, maybe I should have, and
it's actually possible it comes up again in Wayland, of course. But at
first, screen sharing didn't work of course, so it's coming a much
further way. After making screen sharing work, though, the bug didn't
occur again, so I consider this a Xorg-specific problem until further
notice.)
There were also frustrating glitches in the UI, in general. I actually
had to setup a compositor alongside i3 to make things bearable at
all. Video playback in a window was laggy, sluggish, and out of sync.
Wayland fixed all of this.
Wayland equivalents
This section documents each tool I have picked as an alternative to
the current Xorg tool I am using for the task at hand. It also touches
on other alternatives and how the tool was configured.
Note that this list is based on the series of tools I use in
desktop.
TODO: update desktop with the following when done,
possibly moving old configs to a ?xorg archive.
Window manager: i3 sway
This seems like kind of a no-brainer. Sway is around, it's
feature-complete, and it's in Debian.
I'm a bit worried about the "Drew DeVault community", to be
honest. There's a certain aggressiveness in the community I don't like
so much; at least an open hostility towards more modern UNIX tools
like containers and systemd that make it hard to do my work while
interacting with that community.
I'm also concern about the lack of unit tests and user manual for
Sway. The i3 window manager has been designed by a fellow
(ex-)Debian developer I have a lot of respect for (Michael
Stapelberg), partly because of i3 itself, but also working with
him on other projects. Beyond the characters, i3 has a user
guide, a code of conduct, and lots more
documentation. It has a test suite.
Sway has... manual pages, with the homepage just telling users to use
man -k sway to find what they need. I don't think we need that kind
of elitism in our communities, to put this bluntly.
But let's put that aside: Sway is still a no-brainer. It's the easiest
thing to migrate to, because it's mostly compatible with i3. I had
to immediately fix those resources to get a minimal session going:
i3
Sway
note
set_from_resources
set
no support for X resources, naturally
new_window pixel 1
default_border pixel 1
actually supported in i3 as well
That's it. All of the other changes I had to do (and there were
actually a lot) were all Wayland-specific changes, not
Sway-specific changes. For example, use brightnessctl instead of
xbacklight to change the backlight levels.
See a copy of my full sway/config for details.
Other options include:
dwl: tiling, minimalist, dwm for Wayland, not in Debian
Status bar: py3status waybar
I have invested quite a bit of effort in setting up my status bar with
py3status. It supports Sway directly, and did not actually require
any change when migrating to Wayland.
Unfortunately, I had trouble making nm-applet work. Based on this
nm-applet.service, I found that you need to pass --indicator for
it to show up at all.
In theory, tray icon support was merged in 1.5, but in practice
there are still several limitations, like icons not
clickable. Also, on startup, nm-applet --indicator triggers this
error in the Sway logs:
nov 11 22:34:12 angela sway[298938]: 00:49:42.325 [INFO] [swaybar/tray/host.c:24] Registering Status Notifier Item ':1.47/org/ayatana/NotificationItem/nm_applet'
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet IconPixmap: No such property IconPixmap
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet AttentionIconPixmap: No such property AttentionIconPixmap
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet ItemIsMenu: No such property ItemIsMenu
nov 11 22:36:10 angela sway[313419]: info: fcft.c:838: /usr/share/fonts/truetype/dejavu/DejaVuSans.ttf: size=24.00pt/32px, dpi=96.00
... but that seems innocuous. The tray icon displays but is not
clickable.
Note that there is currently (November 2022) a pull request to
hook up a "Tray D-Bus Menu" which, according to Reddit might fix
this, or at least be somewhat relevant.
If you don't see the icon, check the bar.tray_output property in the
Sway config, try: tray_output *.
The non-working tray was the biggest irritant in my migration. I have
used nmtui to connect to new Wifi hotspots or change connection
settings, but that doesn't support actions like "turn off WiFi".
I eventually fixed this by switching from py3status to
waybar, which was another yak horde shaving session, but
ultimately, it worked.
Web browser: Firefox
Firefox has had support for Wayland for a while now, with the team
enabling it by default in nightlies around January 2022. It's
actually not easy to figure out the state of the port, the meta bug
report is still open and it's huge: it currently (Sept 2022)
depends on 76 open bugs, it was opened twelve (2010) years ago, and
it's still getting daily updates (mostly linking to other tickets).
Firefox 106 presumably shipped with "Better screen sharing for
Windows and Linux Wayland users", but I couldn't quite figure out what
those were.
TL;DR: echo MOZ_ENABLE_WAYLAND=1 >> ~/.config/environment.d/firefox.conf && apt install xdg-desktop-portal-wlr
How to enable it
Firefox depends on this silly variable to start correctly under
Wayland (otherwise it starts inside Xwayland and looks fuzzy and fails
to screen share):
MOZ_ENABLE_WAYLAND=1 firefox
To make the change permanent, many recipes recommend adding this to an
environment startup script:
if [ "$XDG_SESSION_TYPE" == "wayland" ]; then
export MOZ_ENABLE_WAYLAND=1
fi
At least that's the theory. In practice, Sway doesn't actually run any
startup shell script, so that can't possibly work. Furthermore,
XDG_SESSION_TYPE is not actually set when starting Sway from gdm3
which I find really confusing, and I'm not the onlyone. So
the above trick doesn't actually work, even if the environment
(XDG_SESSION_TYPE) is set correctly, because we don't have
conditionals in environment.d(5).
(Note that systemd.environment-generator(7)do support running
arbitrary commands to generate environment, but for some some do not
support user-specific configuration files... Even then it may be a
solution to have a conditional MOZ_ENABLE_WAYLAND environment, but
I'm not sure it would work because ordering between those two isn't
clear: maybe the XDG_SESSION_TYPE wouldn't be set just yet...)
At first, I made this ridiculous script to workaround those
issues. Really, it seems to me Firefox should just parse the
XDG_SESSION_TYPE variable here... but then I realized that Firefox
works fine in Xorg when the MOZ_ENABLE_WAYLAND is set.
So now I just set that variable in environment.d and It Just Works :
MOZ_ENABLE_WAYLAND=1
Screen sharing
Out of the box, screen sharing doesn't work until you install
xdg-desktop-portal-wlr or similar
(e.g. xdg-desktop-portal-gnome on GNOME). I had to reboot for the
change to take effect.
Without those tools, it shows the usual permission prompt with "Use
operating system settings" as the only choice, but when we accept...
nothing happens. After installing the portals, it actualyl works, and
works well!
This was tested in Debian bookworm/testing with Firefox ESR 102 and
Firefox 106.
Major caveat: we can only share a full screen, we can't currently
share just a window. The major upside to that is that, by default,
it streams onlyone output which is actually what I want most
of the time! See the screencast compatibility for more
information on what is supposed to work.
This is actually a huge improvement over the situation in Xorg,
where Firefox can only share a window or all monitors, which led
me to use Chromium a lot for video-conferencing. With this change, in
other words, I will not need Chromium for anything anymore, whoohoo!
If slurp, wofi, or bemenu are
installed, one of them will be used to pick the monitor to share,
which effectively acts as some minimal security measure. See
xdg-desktop-portal-wlr(1) for how to configure that.
Side note: Chrome fails to share a full screen
I was still using Google Chrome (or, more accurately, Debian's
Chromium package) for some videoconferencing. It's mainly because
Chromium was the only browser which will allow me to share only one of
my two monitors, which is extremely useful.
To start chrome with the Wayland backend, you need to use:
If it shows an ugly gray border, check the Use system title bar and
borders setting.
It can do some screensharing. Sharing a window and a tab seems to
work, but sharing a full screen doesn't: it's all black. Maybe not
ready for prime time.
And since Firefox can do what I need under Wayland now, I will not
need to fight with Chromium to work under Wayland:
apt purge chromium
Note that a similar fix was necessary for Signal Desktop, see this
commit. Basically you need to figure out a way to pass those same
flags to signal:
News: feed2exec, gnus
See Email, above, or Emacs in Editor, below.
Editor: Emacs okay-ish
Emacs is being actively ported to Wayland. According to this LWN
article, the first (partial, to Cairo) port was done in 2014 and a
working port (to GTK3) was completed in 2021, but wasn't merged until
late 2021. That is: after Emacs 28 was released (April
2022).
So we'll probably need to wait for Emacs 29 to have native Wayland
support in Emacs, which, in turn, is unlikely to arrive in time for
the Debian bookworm freeze. There are, however, unofficial
builds for both Emacs 28 and 29 provided by spwhitton which
may provide native Wayland support.
I tested the snapshot packages and they do not quite work well
enough. First off, they completely take over the builtin Emacs they
hijack the $PATH in /etc! and certain things are simply not
working in my setup. For example, this hook never gets ran on startup:
(add-hook 'after-init-hook 'server-start t)
Still, like many X11 applications, Emacs mostly works fine under
Xwayland. The clipboard works as expected, for example.
Scaling is a bit of an issue: fonts look fuzzy.
I have heard anecdotal evidence of hard lockups with Emacs running
under Xwayland as well, but haven't experienced any problem so far. I
did experience a Wayland crash with the snapshot version however.
TODO: look again at Wayland in Emacs 29.
Backups: borg
Mostly irrelevant, as I do not use a GUI.
Color theme: srcery, redshift gammastep
I am keeping Srcery as a color theme, in general.
Redshift is another story: it has no support for Wayland out of
the box, but it's apparently possible to apply a hack on the TTY
before starting Wayland, with:
redshift -m drm -PO 3000
This tip is from the arch wiki which also has other suggestions
for Wayland-based alternatives. Both KDE and GNOME have their own "red
shifters", and for wlroots-based compositors, they (currently,
Sept. 2022) list the following alternatives:
greetd and QtGreet (former in Debian, not latter, which
means we're stuck with the weird agreety which doesn't work at
all)
sddm: KDE's default, in Debian, probably heavier or as heavy as
gdm3
Terminal: xterm foot
One of the biggest question mark in this transition was what to do
about Xterm. After writing twoarticles about terminal
emulators as a professional journalist, decades of working on the
terminal, and probably using dozens of different terminal emulators,
I'm still not happy with any of them.
This is such a big topic that I actually have an entire blog post
specifically about this.
For starters, using xterm under Xwayland works well enough, although
the font scaling makes things look a bit too fuzzy.
I have also tried foot: it ... just works!
Fonts are much crisper than Xterm and Emacs. URLs are not clickable
but the URL selector (control-shift-u) is just plain
awesome (think "vimperator" for the terminal).
There's cool hack to jump between prompts.
Copy-paste works. True colors work. The word-wrapping is excellent: it
doesn't lose one byte. Emojis are nicely sized and colored. Font
resize works. There's even scroll back search
(control-shift-r).
Foot went from a question mark to being a reason to switch to Wayland,
just for this little goodie, which says a lot about the quality of
that software.
The selection clicks are a not quite what I would expect though. In
rxvt and others, you have the following patterns:
single click: reset selection, or drag to select
double: select word
triple: select quotes or line
quadruple: select line
I particularly find the "select quotes" bit useful. It seems like foot
just supports double and triple clicks, with word and line
selected. You can select a rectangle with control,. It
correctly extends the selection word-wise with right click if
double-click was first used.
One major problem with Foot is that it's a new terminal, with its own
termcap entry. Support for foot was added to ncurses in the
20210731 release, which was shipped after the current Debian
stable release (Debian bullseye, which ships 6.2+20201114-2). A
workaround for this problem is to install the foot-terminfo package
on the remote host, which is available in Debian stable.
This should eventually resolve itself, as Debian bookworm has a newer
version. Note that some corrections were also shipped in the
20211113 release, but that is also shipped in Debian bookworm.
That said, I am almost certain I will have to revert back to xterm
under Xwayland at some point in the future. Back when I was using
GNOME Terminal, it would mostly work for everything until I had to use
the serial console on a (HP ProCurve) network switch, which have a
fancy TUI that was basically unusable there. I fully expect such
problems with foot, or any other terminal than xterm, for that matter.
The foot wiki has good troubleshooting instructions as well.
Update: I did find one tiny thing to improve with foot, and it's the
default logging level which I found pretty verbose. After discussing
it with the maintainer on IRC, I submitted this patch to tweak
it, which I described like this on Mastodon:
today's reason why i will go to hell when i die (TRWIWGTHWID?): a
600-word, 63 lines commit log for a one line change:
https://codeberg.org/dnkl/foot/pulls/1215
The above list comes partly from https://arewewaylandyet.com/ and
awesome-wayland. It is likely incomplete.
I have read some good things about bemenu, fuzzel, and wofi.
A particularly tricky option is that my rofi password management
depends on xdotool for some operations. At first, I thought this was
just going to be (thankfully?) impossible, because we actually like
the idea that one app cannot send keystrokes to another. But it seems
there are actually alternatives to this, like wtype or
ydotool, the latter which requires root access. wl-ime-type
does that through the input-method-unstable-v2 protocol (sample
emoji picker, but is not packaged in Debian.
As it turns out, wtype just works as expected, and fixing this was
basically a two-line patch. Another alternative, not in Debian, is
wofi-pass.
The other problem is that I actually heavily modified rofi. I use
"modis" which are not actually implemented in wofi or tofi, so I'm
left with reinventing those wheels from scratch or using the rofi +
wayland fork... It's really too bad that fork isn't being
reintegrated...
For now, I'm actually still using rofi under Xwayland. The main
downside is that fonts are fuzzy, but it otherwise just works.
Note that wlogout could be a partial replacement (just for the
"power menu").
Image viewers: geeqie ?
I'm not very happy with geeqie in the first place, and I suspect the
Wayland switch will just make add impossible things on top of the
things I already find irritating (Geeqie doesn't support copy-pasting
images).
In practice, Geeqie doesn't seem to work so well under Wayland. The
fonts are fuzzy and the thumbnail preview just doesn't work anymore
(filed as Debian bug 1024092). It seems it also has problems
with scaling.
Alternatives:
See also this list and that list for other list of image
viewers, not necessarily ported to Wayland.
TODO: pick an alternative to geeqie, nomacs would be gorgeous if it
wouldn't be basically abandoned upstream (no release since 2020), has
an unpatchedCVE-2020-23884 since July 2020, does bad
vendoring, and is in bad shape in Debian (4 minor releases
behind).
So for now I'm still grumpily using Geeqie.
Media player: mpv, gmpc / sublime
This is basically unchanged. mpv seems to work fine under Wayland,
better than Xorg on my new laptop (as mentioned in the introduction),
and that before the version which improves Wayland support
significantly, by bringing native Pipewire support and DMA-BUF
support.
gmpc is more of a problem, mainly because it is abandoned. See
2022-08-22-gmpc-alternatives for the full discussion, one of
the alternatives there will likely support Wayland.
Finally, I might just switch to sublime-music instead... In any
case, not many changes here, thankfully.
Screensaver: xsecurelock swaylock
I was previously using xss-lock and xsecurelock as a screensaver, with
xscreensaver "hacks" as a backend for xsecurelock.
The basic screensaver in Sway seems to be built with swayidle and
swaylock. It's interesting because it's the same "split" design
as xss-lock and xsecurelock.
That, unfortunately, does not include the fancy "hacks" provided by
xscreensaver, and that is unlikely to be implemented upstream.
Other alternatives include gtklock and waylock (zig), which
do not solve that problem either.
It looks like swaylock-plugin, a swaylock fork, which at least
attempts to solve this problem, although not directly using the real
xscreensaver hacks. swaylock-effects is another attempt at this,
but it only adds more effects, it doesn't delegate the image display.
Other than that, maybe it's time to just let go of those funky
animations and just let swaylock do it's thing, which is display a
static image or just a black screen, which is fine by me.
In the end, I am just using swayidle with a configuration based on
the systemd integration wiki page but with additional tweaks from
this service, see the resulting swayidle.service file.
Interestingly, damjan also has a service for swaylock itself,
although it's not clear to me what its purpose is...
Screenshot: maim grim, pubpaste
I'm a heavy user of maim (and a package uploader in Debian). It
looks like the direct replacement to maim (and slop) is grim
(and slurp). There's also swappy which goes on top of grim
and allows preview/edit of the resulting image, nice touch (not in
Debian though).
See also awesome-wayland screenshots for other alternatives:
there are many, including X11 tools like Flameshot that also
support Wayland.
One key problem here was that I have my own screenshot / pastebin
software which will needed an update for Wayland as well. That,
thankfully, meant actually cleaning up a lot of horrible code that
involved calling xterm and xmessage for user interaction. Now,
pubpaste uses GTK for prompts and looks much better. (And before
anyone freaks out, I already had to use GTK for proper clipboard
support, so this isn't much of a stretch...)
Screen recorder: simplescreenrecorder wf-recorder
In Xorg, I have used both peek or simplescreenrecorder for
screen recordings. The former will work in Wayland, but has no
sound support. The latter has a fork with Wayland support but
it is limited and buggy ("doesn't support recording area selection and
has issues with multiple screens").
It looks like wf-recorder will just do everything correctly out
of the box, including audio support (with --audio, duh). It's also
packaged in Debian.
One has to wonder how this works while keeping the "between app
security" that Wayland promises, however... Would installing such a
program make my system less secure?
Many other options are available, see the awesome Wayland
screencasting list.
RSI: workrave nothing?
Workrave has no support for Wayland. activity watch is a
time tracker alternative, but is not a RSI watcher. KDE has
rsiwatcher, but that's a bit too much on the heavy side for my
taste.
SafeEyes looks like an alternative at first, but it has many
issues under Wayland (escape doesn't work, idle doesn't
work, it just doesn't work really). timekpr-nextcould be
an alternative as well, and has support for Wayland.
I am also considering just abandoning workrave, even if I stick with
Xorg, because it apparently introduces significant latency in the
input pipeline.
And besides, I've developed a pretty unhealthy alert fatigue with
Workrave. I have used the program for so long that my fingers know
exactly where to click to dismiss those warnings very effectively. It
makes my work just more irritating, and doesn't fix the fundamental
problem I have with computers.
Other apps
This is a constantly changing list, of course. There's a bit of a
"death by a thousand cuts" in migrating to Wayland because you realize
how many things you were using are tightly bound to X.
.Xresources - just say goodbye to that old resource system, it
was used, in my case, only for rofi, xterm, and ... Xboard!?
keyboard layout switcher: built-in to Sway since 2017 (PR
1505, 1.5rc2+), requires a small configuration change, see
this answer as well, looks something like this command:
That works refreshingly well, even better than in Xorg, I must say.
swaykbdd is an alternative that supports per-window layouts
(in Debian).
wallpaper: currently using feh, will need a replacement, TODO:
figure out something that does, like feh, a random shuffle.
swaybg just loads a single image, duh. oguri might be a
solution, but unmaintained, used here, not in
Debian. wallutils is another option, also not in
Debian. For now I just don't have a wallpaper, the background is a
solid gray, which is better than Xorg's default (which is whatever
crap was left around a buffer by the previous collection of
programs, basically)
notifications: currently using dunst in some places, which
works well in both Xorg and Wayland, not a blocker, salut a
possible alternative (not in Debian), damjan uses mako. TODO:
install dunst everywhere
nov 11 22:34:12 angela sway[298938]: 00:49:42.325 [INFO] [swaybar/tray/host.c:24] Registering Status Notifier Item ':1.47/org/ayatana/NotificationItem/nm_applet'
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet IconPixmap: No such property IconPixmap
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet AttentionIconPixmap: No such property AttentionIconPixmap
nov 11 22:34:12 angela sway[298938]: 00:49:42.327 [ERROR] [swaybar/tray/item.c:127] :1.47/org/ayatana/NotificationItem/nm_applet ItemIsMenu: No such property ItemIsMenu
nov 11 22:36:10 angela sway[313419]: info: fcft.c:838: /usr/share/fonts/truetype/dejavu/DejaVuSans.ttf: size=24.00pt/32px, dpi=96.00
... but it seems innocuous. The tray icon displays but, as stated
above, is not clickable. If you don't see the icon, check the
bar.tray_output property in the Sway config, try: tray_output *.
Note that there is currently (November 2022) a pull request to
hook up a "Tray D-Bus Menu" which, according to Reddit might
fix this, or at least be somewhat relevant.
This was the biggest irritant in my migration. I have used nmtui
to connect to new Wifi hotspots or change connection settings, but
that doesn't support actions like "turn off WiFi".
I eventually fixed this by switching from py3status to
waybar.
window switcher: in i3 I was using this bespoke i3-focus
script, which doesn't work under Sway, swayr an option, not in
Debian. So I put together this other bespoke hack from
multiple sources, which works.
PDF viewer: currently using atril (which supports Wayland), could
also just switch to zatura/mupdf permanently, see also calibre
for a discussion on document viewers
More X11 / Wayland equivalents
For all the tools above, it's not exactly clear what options exist in
Wayland, or when they do, which one should be used. But for some basic
tools, it seems the options are actually quite clear. If that's the
case, they should be listed here:
Note that arandr and autorandr are not directly part of
X. arewewaylandyet.com refers to a few alternatives. We suggest
wdisplays and kanshi above (see also this service
file) but wallutils can also do the autorandr stuff, apparently,
and nwg-displays can do the arandr part. Neither are packaged in
Debian yet.
So I have tried wdisplays and it Just Works, and well. The UI even
looks better and more usable than arandr, so another clean win from
Wayland here.
TODO: test kanshi as a autorandr replacement
Other issues
systemd integration
I've had trouble getting session startup to work. This is partly
because I had a kind of funky system to start my session in the first
place. I used to have my whole session started from .xsession like
this:
But obviously, the xsession.target is not started by the Sway
session. It seems to just start a default.target, which is really
not what we want because we want to associate the services directly
with the graphical-session.target, so that they don't start when
logging in over (say) SSH.
damjan on #debian-systemd showed me his sway-setup which
features systemd integration. It involves starting a different session
in a completely new .desktop file. That work was submitted
upstream but refused on the grounds that "I'd rather not give a
preference to any particular init system." Another PR was
abandoned because "restarting sway does not makes sense: that
kills everything".
The work was therefore moved to the wiki.
So. Not a great situation. The upstream wikisystemd
integration suggests starting the systemd target from within
Sway, which has all sorts of problems:
you don't get Sway logs anywhere
control groups are all messed up
I have done a lot of work trying to figure this out, but I remember
that starting systemd from Sway didn't actually work for me: my
previously configured systemd units didn't correctly start, and
especially not with the right $PATH and environment.
So I went down that rabbit hole and managed to correctly configure
Sway to be started from the systemd --user session.
I have partly followed the wiki but also picked ideas from damjan's
sway-setup and xdbob's sway-services. Another option is
uwsm (not in Debian).
This is the config I have in .config/systemd/user/:
You will also need at least part of my sway/config, which
sends the systemd notification (because, no, Sway doesn't support any
sort of readiness notification, that would be too easy). And you might
like to see my swayidle-config while you're there.
Finally, you need to hook this up somehow to the login manager. This
is typically done with a desktop file, so drop
sway-session.desktop in /usr/share/wayland-sessions and
sway-user-service somewhere in your $PATH (typically
/usr/bin/sway-user-service).
The session then looks something like this:
Environment propagation
At first, my terminals and rofi didn't have the right $PATH, which
broke a lot of my workflow. It's hard to tell exactly how Wayland
gets started or where to inject environment. This discussion
suggests a few alternatives and this Debian bug report discusses
this issue as well.
I eventually picked environment.d(5) since I already manage my user
session with systemd, and it fixes a bunch of other problems. I used
to have a .shenv that I had to manually source everywhere. The only
problem with that approach is that it doesn't support conditionals,
but that's something that's rarely needed.
Pipewire
This is a whole topic onto itself, but migrating to Wayland also
involves using Pipewire if you want screen sharing to work. You
can actually keep using Pulseaudio for audio, that said, but that
migration is actually something I've wanted to do anyways: Pipewire's
design seems much better than Pulseaudio, as it folds in JACK
features which allows for pretty neat tricks. (Which I should probably
show in a separate post, because this one is getting rather long.)
I first tried this migration in Debian bullseye, and it didn't work
very well. Ardour would fail to export tracks and I would get
into weird situations where streams would just drop mid-way.
A particularly funny incident is when I was in a meeting and I
couldn't hear my colleagues speak anymore (but they could) and I went
on blabbering on my own for a solid 5 minutes until I realized what
was going on. By then, people had tried numerous ways of letting me
know that something was off, including (apparently) coughing, saying
"hello?", chat messages, IRC, and so on, until they just gave up and
left.
I suspect that was also a Pipewire bug, but it could also have been
that I muted the tab by error, as I recently learned that clicking on
the little tiny speaker icon on a tab mutes that tab. Since the tab
itself can get pretty small when you have lots of them, it's actually
quite frequently that I mistakenly mute tabs.
Anyways. Point is: I already knew how to make the migration, and I had
already documented how to make the change in Puppet. It's
basically:
An optional (but key, IMHO) configuration you should also make is to
"switch on connect", which will make your Bluetooth or USB headset
automatically be the default route for audio, when connected. In
~/.config/pipewire/pipewire-pulse.conf.d/autoconnect.conf:
See the excellent as usual Arch wiki page about Pipewire for
that trick and more information about Pipewire. Note that you must
not put the file in ~/.config/pipewire/pipewire.conf (or
pipewire-pulse.conf, maybe) directly, as that will break your
setup. If you want to add to that file, first copy the template from
/usr/share/pipewire/pipewire-pulse.conf first.
So far I'm happy with Pipewire in bookworm, but I've heard mixed
reports from it. I have high hopes it will become the standard media
server for Linux in the coming months or years, which is great because
I've been (rather boldly, I admit) on the record saying I don't like
PulseAudio.
Rereading this now, I feel it might have been a little unfair, as
"over-engineered and tries to do too many things at once" applies
probably even more to Pipewire than PulseAudio (since it also handles
video dispatching).
That said, I think Pipewire took the right approach by implementing
existing interfaces like Pulseaudio and JACK. That way we're not
adding a third (or fourth?) way of doing audio in Linux; we're just
making the server better.
Keypress drops
Sometimes I lose keyboard presses. This correlates with the following
warning from Sway:
d c 06 10:36:31 curie sway[343384]: 23:32:14.034 [ERROR] [wlr] [libinput] event5 - SONiX USB Keyboard: client bug: event processing lagging behind by 37ms, your system is too slow
... and corresponds to an open bug report in Sway. It seems the
"system is too slow" should really be "your compositor is too slow"
which seems to be the case here on this older system
(curie). It doesn't happen often, but it does happen,
particularly when a bunch of busy processes start in parallel (in my
case: a linter running inside a container and notmuch new).
The proposed fix for this in Sway is to gain real time privileges
and add the CAP_SYS_NICE capability to the binary. We'll see how
that goes in Debian once 1.8 gets released and shipped.
Improvements over i3
Tiling improvements
There's a lot of improvements Sway could bring over using plain
i3. There are pretty neat auto-tilers that could replicate the
configurations I used to have in Xmonad or Awesome, see:
Display latency tweaks
TODO: You can tweak the display latency in wlroots compositors with the
max_render_time parameter, possibly getting lower latency than
X11 in the end.
Sound/brightness changes notifications
TODO: Avizo can display a pop-up to give feedback on volume and
brightness changes. Not in Debian. Other alternatives include
SwayOSD and sway-nc, also not in Debian.
Debugging tricks
The xeyes (in the x11-apps package) will run in Wayland, and can
actually be used to easily see if a given window is also in
Wayland. If the "eyes" follow the cursor, the app is actually running
in xwayland, so not natively in Wayland.
Another way to see what is using Wayland in Sway is with the command:
Conclusion
In general, this took me a long time, but it mostly works. The tray
icon situation is pretty frustrating, but there's a workaround and I
have high hopes it will eventually fix itself. I'm also actually
worried about the DisplayLink support because I eventually want to
be using this, but hopefully that's another thing that will hopefully
fix itself before I need it.
A word on the security model
I'm kind of worried about all the hacks that have been added to
Wayland just to make things work. Pretty much everywhere we need to,
we punched a hole in the security model:
windows can overlay on top of each other (so one app could, for
example, spoof a password dialog, through the layer-shell
protocol)
Wikipedia describes the security properties of Wayland as it
"isolates the input and output of every window, achieving
confidentiality, integrity and availability for both." I'm not sure
those are actually realized in the actual implementation, because of
all those holes punched in the design, at least in Sway. For example,
apparently the GNOME compositor doesn't have the virtual-keyboard
protocol, but they do have (another?!) text input protocol.
Wayland does offer a better basis to implement such a system,
however. It feels like the Linux applications security model lacks
critical decision points in the UI, like the user approving "yes, this
application can share my screen now". Applications themselves might
have some of those prompts, but it's not mandatory, and that is
worrisome.
In my tubman setup, I started using ZFS on an old server
I had lying around. The machine is really old though (2011!) and it
"feels" pretty slow. I want to see how much of that is ZFS and how
much is the machine. Synthetic benchmarks show that ZFS may be slower
than mdadm in RAID-10 or RAID-6 configuration, so I want to confirm
that on a live workload: my workstation. Plus, I want easy, regular,
high performance backups (with send/receive snapshots) and there's no
way I'm going to use BTRFS because I find
it too confusing and unreliable.
So off we go.
Installation
Since this is a conversion (and not a new install), our procedure is
slightly different than the official documentation but otherwise
it's pretty much in the same spirit: we're going to use ZFS for
everything, including the root filesystem.
So, install the required packages, on the current system:
root@curie:/home/anarcat# sgdisk -p /dev/sdc
Disk /dev/sdc: 1953525168 sectors, 931.5 GiB
Model: ESD-S1C
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): [REDACTED]
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 1953525134
Partitions will be aligned on 16-sector boundaries
Total free space is 14 sectors (7.0 KiB)
Number Start (sector) End (sector) Size Code Name
1 48 2047 1000.0 KiB EF02
2 2048 1050623 512.0 MiB EF00
3 1050624 3147775 1024.0 MiB BF01
4 3147776 1953525134 930.0 GiB BF00
Unfortunately, we can't be sure of the sector size here, because the
USB controller is probably lying to us about it. Normally, this
smartctl command should tell us the sector size as well:
root@curie:~# smartctl -i /dev/sdb -qnoserial
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-14-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Black Mobile
Device Model: WDC WD10JPLX-00MBPT0
Firmware Version: 01.01H01
User Capacity: 1 000 204 886 016 bytes [1,00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 6
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue May 17 13:33:04 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Above is the example of the builtin HDD drive. But the SSD device
enclosed in that USB controller doesn't support SMART commands,
so we can't trust that it really has 512 bytes sectors.
This matters because we need to tweak the ashift value
correctly. We're going to go ahead the SSD drive has the common 4KB
settings, which means ashift=12.
Note here that we are not creating a separate partition for
swap. Swap on ZFS volumes (AKA "swap on ZVOL") can trigger lockups and
that issue is still not fixed upstream. Ubuntu recommends using a
separate partition for swap instead. But since this is "just" a
workstation, we're betting that we will not suffer from this problem,
after hearing a report from another Debian developer running this
setup on their workstation successfully.
We do not recommend this setup though. In fact, if I were to redo this
partition scheme, I would probably use LUKS encryption and setup a
dedicated swap partition, as I had problems with ZFS encryption as
well.
Creating pools
ZFS pools are somewhat like "volume groups" if you are familiar with
LVM, except they obviously also do things like RAID-10. (Even though
LVM can technically also do RAID, people typically use mdadm
instead.)
In any case, the guide suggests creating two different pools here:
one, in cleartext, for boot, and a separate, encrypted one, for the
rest. Technically, the boot partition is required because the Grub
bootloader only supports readonly ZFS pools, from what I
understand. But I'm a little out of my depth here and just following
the guide.
Boot pool creation
This creates the boot pool in readonly mode with features that grub
supports:
-O encryption=on -O keylocation=prompt -O keyformat=passphrase:
encryption, prompt for a password, default algorithm is
aes-256-gcm, explicit in the guide, made implicit here
-O acltype=posixacl -O xattr=sa: enable ACLs, with better
performance (not enabled by default)
-O dnodesize=auto: related to extended attributes, less
compatibility with other implementations
-O compression=zstd: enable zstd compression, can be
disabled/enabled by dataset to with zfs set compression=off
rpool/example
-O relatime=on: classic atime optimisation, another that could
be used on a busy server is atime=off
-O canmount=off: do not make the pool mount automatically with
mount -a?
-O mountpoint=/ -R /mnt: mount pool on / in the future, but
/mnt for now
Those settings are all available in zfsprops(8). Other flags are
defined in zpool-create(8). The reasoning behind them is also
explained in the upstream guide and some also in [the Debian
wiki][]. Those flags were actually not used:
-O normalization=formD: normalize file names on comparisons (not
storage), implies utf8only=on, which is a bad idea (and
effectively meant my first sync failed to copy some files,
including this folder from a supysonic checkout). and this
cannot be changed after the filesystem is created. bad, bad, bad.
Side note about single-disk pools
Also note that we're living dangerously here: single-disk ZFS pools
are rumoured to be more dangerous than not running ZFS at all. The
choice quote from this article is:
[...] any error can be detected, but cannot be corrected. This
sounds like an acceptable compromise, but its actually not. The
reason its not is that ZFS' metadata cannot be allowed to be
corrupted. If it is it is likely the zpool will be impossible to
mount (and will probably crash the system once the corruption is
found). So a couple of bad sectors in the right place will mean that
all data on the zpool will be lost. Not some, all. Also there's no
ZFS recovery tools, so you cannot recover any data on the drives.
Compared with (say) ext4, where a single disk error can recovered,
this is pretty bad. But we are ready to live with this with the idea
that we'll have hourly offline snapshots that we can easily recover
from. It's trade-off. Also, we're running this on a NVMe/M.2 drive
which typically just blinks out of existence completely, and doesn't
"bit rot" the way a HDD would.
Also, the FreeBSD handbook quick start doesn't have any warnings
about their first example, which is with a single disk. So I am
reassured at least.
Creating mount points
Next we create the actual filesystems, known as "datasets" which are
the things that get mounted on mountpoint and hold the actual files.
Note that it's unclear to me why those datasets are necessary, but
they seem common practice, also used in this FreeBSD
example. The OpenZFS guide mentions the Solaris upgrades and
Ubuntu's zsys that use that container for upgrades and rollbacks.
This blog post seems to explain a bit the layout behind the
installer.
this creates the actual boot and root filesystems:
Notice here a peculiarity: we must create rpool/var/lib to
create rpool/var/lib/docker otherwise we get this error:
cannot create 'rpool/var/lib/docker': parent does not exist
... and no, just creating /mnt/var/lib doesn't fix that
problem. In fact, it makes things even more confusing because an
existing directory shadows a mountpoint, which is the opposite of
how things normally work.
Also note that you will probably need to change storage driver in
Docker, see the zfs-driver documentation for details but,
basically, I did:
Now that we have everything setup and mounted, let's copy all files
over.
Copying files
This is a list of all the mounted filesystems
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
You can check that the list is correct with:
mount -l -t ext4,btrfs,vfat awk ' print $3 '
Note that we skip /srv as it's on a different disk.
On the first run, we had:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
16,831,437 100% 184.14MB/s 0:00:00 (xfr#101, to-chk=0/110)
syncing / to /mnt/...
28,019,293,280 94% 47.63MB/s 0:09:21 (xfr#703710, ir-chk=6748/839220)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,267,990 98% 50.71MB/s 0:10:40 (xfr#736577, to-chk=0/867732)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
24,456,268,098 98% 68.03MB/s 0:05:42 (xfr#159867, ir-chk=6875/172377)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/B3AB0CDA9C4454B3C1197E5A22669DF8EE849D90"
199,762,528,125 93% 74.82MB/s 0:42:26 (xfr#1437846, ir-chk=1018/1983979)rsync: [generator] recv_generator: mkdir "/mnt/home/anarcat/dist/supysonic/tests/assets/\#346" failed: Invalid or incomplete multibyte or wide character (84)
*** Skipping any contents from this failed directory ***
315,384,723,978 96% 76.82MB/s 1:05:15 (xfr#2256473, to-chk=0/2993950)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Note the failure to transfer that supysonic file? It turns out they
had a weird filename in their source tree, since then removed,
but still it showed how the utf8only feature might not be such a bad
idea. At this point, the procedure was restarted all the way back to
"Creating pools", after unmounting all ZFS filesystems (umount
/mnt/run /mnt/boot/efi && umount -t zfs -a) and destroying the pool,
which, surprisingly, doesn't require any confirmation (zpool destroy
rpool).
The second run was cleaner:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/110)
syncing / to /mnt/...
28,019,033,070 97% 42.03MB/s 0:10:35 (xfr#703671, ir-chk=1093/833515)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,807,102 98% 44.84MB/s 0:12:04 (xfr#736580, to-chk=0/867723)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
IO error encountered -- skipping file deletion
24,043,086,450 96% 62.03MB/s 0:06:09 (xfr#151819, ir-chk=15117/172571)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/4C1FDBFEA976FF924D062FB990B24B897A77B84B"
315,423,626,507 96% 67.09MB/s 1:14:43 (xfr#2256845, to-chk=0/2994364)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Also note the transfer speed: we seem capped at 76MB/s, or
608Mbit/s. This is not as fast as I was expecting: the USB connection
seems to be at around 5Gbps:
anarcat@curie:~$ lsusb -tv head -4
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/6p, 5000M
ID 1d6b:0003 Linux Foundation 3.0 root hub
__ Port 1: Dev 4, If 0, Class=Mass Storage, Driver=uas, 5000M
ID 0b05:1932 ASUSTek Computer, Inc.
So it shouldn't cap at that speed. It's possible the USB adapter is
failing to give me the full speed though. It's not the M.2 SSD drive
either, as that has a ~500MB/s bandwidth, acccording to its spec.
At this point, we're about ready to do the final configuration. We
drop to single user mode and do the rest of the procedure. That used
to be shutdown now, but it seems like the systemd switch broke that,
so now you can reboot into grub and pick the "recovery"
option. Alternatively, you might try systemctl rescue, as I found
out.
I also wanted to copy the drive over to another new NVMe drive, but
that failed: it looks like the USB controller I have doesn't work with
older, non-NVME drives.
Boot configuration
Now we need to enter the new system to rebuild the boot loader and
initrd and so on.
First, we bind mounts and chroot into the ZFS disk:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
Next we add an extra service that imports the bpool on boot, to make
sure it survives a zpool.cache destruction:
I had to trim down /etc/fstab and /etc/crypttab to only contain
references to the legacy filesystems (/srv is still BTRFS!).
If we don't already have a tmpfs defined in /etc/fstab:
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
test
read I/O
read IOPS
write I/O
write IOPS
rand4k4g1x
39.27
10052
212.15
54310
rand4k4g1x--fsync=1
39.29
10057
2.73
699
rand64k256m16x
1297.00
20751
1068.57
17097
rand64k256m16x--fsync=1
1290.90
20654
353.82
5661
rand1m16g1x
315.15
315
563.77
563
rand1m16g1x--fsync=1
345.88
345
157.01
157
Peaks are at about 20k IOPS and ~1.3GiB/s read, 1GiB/s write in the
64KB blocks with 16 jobs.
Slowest is the random 4k block sync write at an abysmal 3MB/s and 700
IOPS The 1MB read/write tests have lower IOPS, but that is expected.
Rescue test, ZFS
This test was also performed in rescue mode.
Raw numbers, from the ?job-curie-zfs.log, converted to MiB/s and
manually merged:
test
read I/O
read IOPS
write I/O
write IOPS
rand4k4g1x
77.20
19763
27.13
6944
rand4k4g1x--fsync=1
76.16
19495
6.53
1673
rand64k256m16x
1882.40
30118
70.58
1129
rand64k256m16x--fsync=1
1865.13
29842
71.98
1151
rand1m16g1x
921.62
921
102.21
102
rand1m16g1x--fsync=1
908.37
908
64.30
64
Peaks are at 1.8GiB/s read, also in the 64k job like above, but much
faster. The write is, as expected, much slower at 70MiB/s (compared
to 1GiB/s!), but it should be noted the sync write doesn't degrade
performance compared to async writes (although it's still below the
LVM 300MB/s).
Conclusions
Really, ZFS has trouble performing in all write conditions. The
random 4k sync write test is the only place where ZFS outperforms
LVM in writes, and barely (7MiB/s vs 3MiB/s). Everywhere else, writes
are much slower, sometimes by an order of magnitude.
And before some ZFS zealot jumps in talking about the SLOG or some
other cache that could be added to improved performance, I'll remind
you that those numbers are on a bare bones NVMe drive, pretty much as
fast storage as you can find on this machine. Adding another NVMe
drive as a cache probably will not improve write performance here.
Still, those are very different results than the tests performed by
Salter which shows ZFS beating traditional configurations in all
categories but uncached 4k reads (not writes!). That said, those tests
are very different from the tests I performed here, where I test
writes on a single disk, not a RAID array, which might explain the
discrepancy.
Also, note that neither LVM or ZFS manage to reach the 2400MB/s read
and 1750MB/s write performance specification. ZFS does manage to reach
82% of the read performance (1973MB/s) and LVM 64% of the write
performance (1120MB/s). LVM hits 57% of the read performance and ZFS
hits barely 6% of the write performance.
Overall, I'm a bit disappointed in the ZFS write performance here, I
must say. Maybe I need to tweak the record size or some other ZFS
voodoo, but I'll note that I didn't have to do any such configuration
on the other side to kick ZFS in the pants...
Real world experience
This section document not synthetic backups, but actual real world
workloads, comparing before and after I switched my workstation to
ZFS.
Docker performance
I had the feeling that running some git hook (which was firing a
Docker container) was "slower" somehow. It seems that, at runtime, ZFS
backends are significant slower than their overlayfs/ext4 equivalent:
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:53 curie dockerd[1723]: time="2022-05-16T14:42:53.087219426-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 pid=151170
May 16 14:42:53 curie systemd[1]: Started libcontainer container af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.
May 16 14:42:54 curie systemd[1]: docker-af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.scope: Succeeded.
May 16 14:42:54 curie dockerd[1723]: time="2022-05-16T14:42:54.047297800-04:00" level=info msg="shim disconnected" id=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10
May 16 14:42:54 curie dockerd[998]: time="2022-05-16T14:42:54.051365015-04:00" level=info msg="ignoring event" container=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 16 14:42:54 curie systemd[2444]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[2444]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
Translating this:
container setup: ~1 second
container runtime: ~1 second
container teardown: ~1 second
total runtime: 2-3 seconds
Obviously, those timestamps are not quite accurate enough to make
precise measurements...
After I switched to ZFS:
mai 30 15:31:39 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:39 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:40 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:40 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:41 curie dockerd[3199]: time="2022-05-30T15:31:41.551403693-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 pid=141080
mai 30 15:31:41 curie systemd[1]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[5287]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[1]: Started libcontainer container 42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.
mai 30 15:31:45 curie systemd[1]: docker-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.scope: Succeeded.
mai 30 15:31:45 curie dockerd[3199]: time="2022-05-30T15:31:45.883019128-04:00" level=info msg="shim disconnected" id=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142
mai 30 15:31:45 curie dockerd[1726]: time="2022-05-30T15:31:45.883064491-04:00" level=info msg="ignoring event" container=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
mai 30 15:31:45 curie systemd[1]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
That's double or triple the run time, from 2 seconds to 6
seconds. Most of the time is spent in run time, inside the
container. Here's the breakdown:
container setup: ~2 seconds
container run: ~4 seconds
container teardown: ~1 second
total run time: about ~6-7 seconds
That's a two- to three-fold increase! Clearly something is going on
here that I should tweak. It's possible that code path is less
optimized in Docker. I also worry about podman, but apparently it
also supports ZFS backends. Possibly it would perform better, but
at this stage I wouldn't have a good comparison: maybe it would have
performed better on non-ZFS as well...
Interactivity
While doing the offsite backups (below), the system became somewhat
"sluggish". I felt everything was slow, and I estimate it introduced
~50ms latency in any input device.
Arguably, those are all USB and the external drive was connected
through USB, but I suspect the ZFS drivers are not as well tuned with
the scheduler as the regular filesystem drivers...
Recovery procedures
For test purposes, I unmounted all systems during the procedure:
umount /mnt/boot/efi /mnt/boot/run
umount -a -t zfs
zpool export -a
And disconnected the drive, to see how I would recover this system
from another Linux system in case of a total motherboard failure.
To import an existing pool, plug the device, then import the pool with
an alternate root, so it doesn't mount over your existing filesystems,
then you mount the root filesystem and all the others:
zpool import -l -a -R /mnt &&
zfs mount rpool/ROOT/debian &&
zfs mount -a &&
mount /dev/sdc2 /mnt/boot/efi &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
Offsite backup
Part of the goal of using ZFS is to simplify and harden backups. I
wanted to experiment with shorter recovery times specifically both
point in time recovery objective and recovery time objective
and faster incremental backups.
This is, therefore, part of my backup services.
This section documents how an external NVMe enclosure was setup in a
pool to mirror the datasets from my workstation.
The final setup should include syncoid copying datasets to the backup
server regularly, but I haven't finished that configuration yet.
Partitioning
The above partitioning procedure used sgdisk, but I couldn't figure
out how to do this with sgdisk, so this uses sfdisk to dump the
partition from the first disk to an external, identical drive:
First sync
I used syncoid to copy all pools over to the external device. syncoid
is a thing that's part of the sanoid project which is
specifically designed to sync snapshots between pool, typically over
SSH links but it can also operate locally.
The sanoid command had a --readonly argument to simulate changes,
but syncoid didn't so I tried to fix that with an upstream PR.
It seems it would be better to do this by hand, but this was much
easier. The full first sync was:
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
Funny how the CRITICAL ERROR doesn't actually stop syncoid and it
just carries on merrily doing when it's telling you it's "cowardly
refusing to destroy your existing target"... Maybe that's because my pull
request broke something though...
During the transfer, the computer was very sluggish: everything feels
like it has ~30-50ms latency extra:
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
I wonder how much of that is due to syncoid, particularly because I
often saw mbuffer and pv in there which are not strictly necessary
to do those kind of operations, as far as I understand.
Once that's done, export the pools to disconnect the drive:
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcosv1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
If you ve done anything in the Kubernetes space in recent years, you ve most likely come across the words Service Mesh . It s backed by a set of mature technologies that provides cross-cutting networking, security, infrastructure capabilities to be used by workloads running in Kubernetes in a manner that is transparent to the actual workload. This abstraction enables application developers to not worry about building in otherwise sophisticated capabilities for networking, routing, circuit-breaking and security, and simply rely on the services offered by the service mesh.In this post, I ll be covering Linkerd, which is an alternative to Istio. It has gone through a significant re-write when it transitioned from the JVM to a Go-based Control Plane and a Rust-based Data Plane a few years back and is now a part of the CNCF and is backed by Buoyant. It has proven itself widely for use in production workloads and has a healthy community and release cadence.It achieves this with a side-car container that communicates with a Linkerd control plane that allows central management of policy, telemetry, mutual TLS, traffic routing, shaping, retries, load balancing, circuit-breaking and other cross-cutting concerns before the traffic hits the container. This has made the task of implementing the application services much simpler as it is managed by container orchestrator and service mesh. I covered Istio in a prior post a few years back, and much of the content is still applicable for this post, if you d like to have a look.Here are the broad architectural components of Linkerd:The components are separated into the control plane and the data plane.The control plane components live in its own namespace and consists of a controller that the Linkerd CLI interacts with via the Kubernetes API. The destination service is used for service discovery, TLS identity, policy on access control for inter-service communication and service profile information on routing, retries, timeouts. The identity service acts as the Certificate Authority which responds to Certificate Signing Requests (CSRs) from proxies for initialization and for service-to-service encrypted traffic. The proxy injector is an admission webhook that injects the Linkerd proxy side car and the init container automatically into a pod when the linkerd.io/inject: enabled is available on the namespace or workload.On the data plane side are two components. First, the init container, which is responsible for automatically forwarding incoming and outgoing traffic through the Linkerd proxy via iptables rules. Second, the Linkerd proxy, which is a lightweight micro-proxy written in Rust, is the data plane itself.I will be walking you through the setup of Linkerd (2.12.2 at the time of writing) on a Kubernetes cluster.Let s see what s running on the cluster currently. This assumes you have a cluster running and kubectl is installed and available on the PATH.
On most systems, this should be sufficient to setup the CLI. You may need to restart your terminal to load the updated paths. If you have a non-standard configuration and linkerd is not found after the installation, add the following to your PATH to be able to find the cli:
export PATH=$PATH:~/.linkerd2/bin/
At this point, checking the version would give you the following:
$ linkerd version Client version: stable-2.12.2 Server version: unavailable
Setting up Linkerd Control PlaneBefore installing Linkerd on the cluster, run the following step to check the cluster for pre-requisites:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
pre-kubernetes-setup -------------------- control plane namespace does not already exist can create non-namespaced resources can create ServiceAccounts can create Services can create Deployments can create CronJobs can create ConfigMaps can create Secrets can read Secrets can read extension-apiserver-authentication configmap no clock skew detected
linkerd-version --------------- can determine the latest version cli is up-to-date
Status check results are
All the pre-requisites appear to be good right now, and so installation can proceed.The first step of the installation is to setup the Custom Resource Definitions (CRDs) that Linkerd requires. The linkerd cli only prints the resource YAMLs to standard output and does not create them directly in Kubernetes, so you would need to pipe the output to kubectl apply to create the resources in the cluster that you re working with.
$ linkerd install --crds kubectl apply -f - Rendering Linkerd CRDs... Next, run linkerd install kubectl apply -f - to install the control plane.
customresourcedefinition.apiextensions.k8s.io/authorizationpolicies.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/httproutes.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/meshtlsauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/networkauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serverauthorizations.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/servers.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serviceprofiles.linkerd.io created
Next, install the Linkerd control plane components in the same manner, this time without the crds switch:
$ linkerd install kubectl apply -f - namespace/linkerd created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-identity created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-identity created serviceaccount/linkerd-identity created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-destination created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-destination created serviceaccount/linkerd-destination created secret/linkerd-sp-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-sp-validator-webhook-config created secret/linkerd-policy-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-policy-validator-webhook-config created clusterrole.rbac.authorization.k8s.io/linkerd-policy created clusterrolebinding.rbac.authorization.k8s.io/linkerd-destination-policy created role.rbac.authorization.k8s.io/linkerd-heartbeat created rolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created serviceaccount/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created serviceaccount/linkerd-proxy-injector created secret/linkerd-proxy-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-proxy-injector-webhook-config created configmap/linkerd-config created secret/linkerd-identity-issuer created configmap/linkerd-identity-trust-roots created service/linkerd-identity created service/linkerd-identity-headless created deployment.apps/linkerd-identity created service/linkerd-dst created service/linkerd-dst-headless created service/linkerd-sp-validator created service/linkerd-policy created service/linkerd-policy-validator created deployment.apps/linkerd-destination created cronjob.batch/linkerd-heartbeat created deployment.apps/linkerd-proxy-injector created service/linkerd-proxy-injector created secret/linkerd-config-overrides created
Kubernetes will start spinning up the data plane components and you should see the following when you list the pods:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
linkerd-existence ----------------- 'linkerd-config' config map exists heartbeat ServiceAccount exist control plane replica sets are ready no unschedulable pods control plane pods are ready cluster networks contains all pods cluster networks contains all services
linkerd-config -------------- control plane Namespace exists control plane ClusterRoles exist control plane ClusterRoleBindings exist control plane ServiceAccounts exist control plane CustomResourceDefinitions exist control plane MutatingWebhookConfigurations exist control plane ValidatingWebhookConfigurations exist proxy-init container runs as root user if docker container runtime is used
linkerd-identity ---------------- certificate config is valid trust anchors are using supported crypto algorithm trust anchors are within their validity period trust anchors are valid for at least 60 days issuer cert is using supported crypto algorithm issuer cert is within its validity period issuer cert is valid for at least 60 days issuer cert is issued by the trust anchor
linkerd-webhooks-and-apisvc-tls ------------------------------- proxy-injector webhook has valid cert proxy-injector cert is valid for at least 60 days sp-validator webhook has valid cert sp-validator cert is valid for at least 60 days policy-validator webhook has valid cert policy-validator cert is valid for at least 60 days
linkerd-version --------------- can determine the latest version cli is up-to-date
control-plane-version --------------------- can retrieve the control plane version control plane is up-to-date control plane and cli versions match
linkerd-control-plane-proxy --------------------------- control plane proxies are healthy control plane proxies are up-to-date control plane proxies and cli versions match
Status check results are
Everything looks good.Setting up the Viz ExtensionAt this point, the required components for the service mesh are setup, but let s also install the viz extension, which provides a good visualization capabilities that will come in handy subsequently. Once again, linkerd uses the same pattern for installing the extension.
$ linkerd viz install kubectl apply -f - namespace/linkerd-viz created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created serviceaccount/metrics-api created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created serviceaccount/prometheus created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-admin created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-delegator created serviceaccount/tap created rolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-reader created secret/tap-k8s-tls created apiservice.apiregistration.k8s.io/v1alpha1.tap.linkerd.io created role.rbac.authorization.k8s.io/web created rolebinding.rbac.authorization.k8s.io/web created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-admin created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created serviceaccount/web created server.policy.linkerd.io/admin created authorizationpolicy.policy.linkerd.io/admin created networkauthentication.policy.linkerd.io/kubelet created server.policy.linkerd.io/proxy-admin created authorizationpolicy.policy.linkerd.io/proxy-admin created service/metrics-api created deployment.apps/metrics-api created server.policy.linkerd.io/metrics-api created authorizationpolicy.policy.linkerd.io/metrics-api created meshtlsauthentication.policy.linkerd.io/metrics-api-web created configmap/prometheus-config created service/prometheus created deployment.apps/prometheus created service/tap created deployment.apps/tap created server.policy.linkerd.io/tap-api created authorizationpolicy.policy.linkerd.io/tap created clusterrole.rbac.authorization.k8s.io/linkerd-tap-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-tap-injector created serviceaccount/tap-injector created secret/tap-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-tap-injector-webhook-config created service/tap-injector created deployment.apps/tap-injector created server.policy.linkerd.io/tap-injector-webhook created authorizationpolicy.policy.linkerd.io/tap-injector created networkauthentication.policy.linkerd.io/kube-api-server created service/web created deployment.apps/web created serviceprofile.linkerd.io/metrics-api.linkerd-viz.svc.cluster.local created serviceprofile.linkerd.io/prometheus.linkerd-viz.svc.cluster.local created
A few seconds later, you should see the following in your pod list:
The viz components live in the linkerd-viz namespace.You can now checkout the viz dashboard:
$ linkerd viz dashboard Linkerd dashboard available at: http://localhost:50750 Grafana dashboard available at: http://localhost:50750/grafana Opening Linkerd dashboard in the default browser Opening in existing browser session.
The Meshed column indicates the workload that is currently integrated with the Linkerd control plane. As you can see, there are no application deployments right now that are running.Injecting the Linkerd Data Plane componentsThere are two ways to integrate Linkerd to the application containers:1 by manually injecting the Linkerd data plane components 2 by instructing Kubernetes to automatically inject the data plane componentsInject Linkerd data plane manuallyLet s try the first option. Below is a simple nginx-app that I will deploy into the cluster:
Back in the viz dashboard, I do see the workload deployed, but it isn t currently communicating with the Linkerd control plane, and so doesn t show any metrics, and the Meshed count is 0:Looking at the Pod s deployment YAML, I can see that it only includes the nginx container:
Let s directly inject the linkerd data plane into this running container. We do this by retrieving the YAML of the deployment, piping it to linkerd cli to inject the necessary components and then piping to kubectl apply the changed resources.
Back in the viz dashboard, the workload now is integrated into Linkerd control plane.Looking at the updated Pod definition, we see a number of changes that the linkerd has injected that allows it to integrate with the control plane. Let s have a look:
At this point, the necessary components are setup for you to explore Linkerd further. You can also try out the jaeger and multicluster extensions, similar to the process of installing and using the viz extension and try out their capabilities.Inject Linkerd data plane automaticallyIn this approach, we shall we how to instruct Kubernetes to automatically inject the Linkerd data plane to workloads at deployment time.We can achieve this by adding the linkerd.io/inject annotation to the deployment descriptor which causes the proxy injector admission hook to execute and inject linkerd data plane components automatically at the time of deployment.
This annotation can also be specified at the namespace level to affect all the workloads within the namespace. Note that any resources created before the annotation was added to the namespace will require a rollout restart to trigger the injection of the Linkerd components.Uninstalling LinkerdNow that we have walked through the installation and setup process of Linkerd, let s also cover how to remove it from the infrastructure and go back to the state prior to its installation.The first step would be to remove extensions, such as viz.
FTP master
This month I accepted 484 and rejected 55 packages. The overall number of packages that got accepted was 492.
Debian LTS
This was my hundredth month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian. Woohoo, There is a party. (yes I am old). Unfortunately there are already 101 completed month listed in the debian-lts-announce archive, so I seem to have counted wrong once. *sigh*, yes I am old.
This month my all in all workload has been 14h.
During that time I uploaded:
[DLA 3168-1] openvswitch security update for one CVE
[graphicsmagick] debdiff for Bullseye sent to security team (update as DLA or via PU?)
[graphicsmagick] prepared upload for Buster
[libvncserver] debdiff for Buster and Bullseye sent to maintainer (no upload yet :-()
I also started to work on virglrenderer.
Last but not least I took care of NEW packages on security-master.
Debian ELTS
This month was the fifty first ELTS month.
During my allocated time I uploaded:
[ELA-719-1] graphicsmagick security update of Jessie and Stretch for one CVE
[ELA-720-1] bluez security update of Jessie and Stretch for three CVEs
marked two CVEs of curl as not-affected for Jessie and Stretch
checked that all patches for dpdk need to be backported, unfortunately that was beyond my capabilities
I also started to work on snapd.
Last but not least I finally managed to become familiar with the git workflow and imported several packages to the salsa repository.
Debian Astro
This month I uploaded new upstream versions or improved packaging of:
I also uploaded a new package pysqm. This software supports the Sky Quality Meters made by Unihedron. I was kindly given an SQM-LU for USB and SQM-LE with network adapter. I plan to put a working Python3 version of the old PySQM software into Debian, package the UDM (Unihedron Device Manager) and finally check the support within Indi.
Debian IoT
This month I uploaded new upstream versions or improved packaging of:
Debian Mobcom
This month I finished the transition of the Osmocom packages, except osmo-mgw and osmo-msc seem to have problems. I have no idea how I can solve this, so help is appreciated.
Other stuff
This month I uploaded new packages:
An Bord Plean la conceded that the N6 Galway City Ring Road was in contravention with the National Climate Action plan.
In planning for how we adapt to and mitigate climate change, the UN IPCC AR6 report summarised the state of research globally and modelled nearly 3000 scenarios. The scenarios that kept us below 2 degrees of warming (our Paris agreement commitments) overwhelmingly depended on a move away from car-dependent societies and relied on car-free cities. This report was signed off by every world government.
All EU and national modelling agrees. Accordingly our national Climate Action plan prepares for this global move from cars. It involves a reduction in car traffic, heavy investment in public transport and active travel (walking and cycling). This is essential as the research shows this works, and takes up to 84% less energy for transport in cities.
The N6GCRR plan ignored this, and assumed an increase in car traffic of up to 49%. It in practice would have locked in car dependency when we don t expect there to be enough materials (lithium, etc for batteries) or energy to support that number of cars.
Across Europe and the world we have seen how to move from cars in cities: rail, reliable bus services with dedicated bus corridors; safe, segregated cycle lanes, public space design that enables walking, cycling by keeping distances short the 15 minute city concept of having schools, shops, transport hubs less than 15 minutes from your door. From Paris, removing 40% of cars from the city, now removing a lane from the Peripherique (its ring road), to Korea where expressways in cities have been removed to improve traffic as part of its better design. In Ireland, Dublin has seen a 49% drop in peak-time traffic over recent decades with improved public transport and cycling.
But in Galway we ve ignored all this: not a kilometre of segregated cycle lane added, as there has been an over 80% drop in pupils cycling to school since the 1980s, amplifying traffic as parents commute to drop them to school, making roads more dangerous. No bus route passes over the Quincentennial bridge.
Rather than fix the traffic in Galway, a ring road would induce more traffic as the existing Bothar na dTreabh / Quincintennial bridge did; the current road opened up Knocknacarra for development; a new motorway to Barna would open up Barna for more development.
This is zombie planning: a roads plan from the 1990s lives on, while our County Development Plan has moved the focus to creating new satellite towns in Ardaun and Garraun instead. When all new business wants to be on the East, the new developments need to be near them; new schools are being built on the East, not the West. Rail is being double-tracked to Oranmore (and on to Athenry) to provide commuter rail to Renmore and the growing towns. This reduces the demand for cross-city commuting.
Active travel and public transport development in the city has been stalled awaiting the ring road. This needs to be implemented as quickly as possible. The bus corridor from Salthill (via the schools) to Oranmore (via the businesses at Ballybrit, Parkmore) needs to be completed; this will involve a bus lane on the bridge. The N6GCRR said this was impossible without a new bridge for cars; Dublin s experience with the quays shows otherwise. If we get a fraction of the drop Dublin has seen, the traffic problem will be solved, as shown when the schools are out for holidays.
The NTA and Galway councils have been stuck in thinking from 30 years ago. They assume that traffic cannot be reduced, only added; the ABP inspector agreed, despite overwhelming evidence elsewhere. We need to implement what has been shown to work elsewhere as quickly as possible; the funding is in place but the will and vision to do so has been lacking.
I first installed Ubuntu when Ubuntu 6.06 LTS Dapper Drake was released. I was brand new to Linux. This was Ubuntu s first LTS release; the very first release of Ubuntu was only a year and a half before. I was impressed by how usable and useful the system was. It soon became my primary home operating system and I wanted to help make it better.
On October 15, 2009, I was helping test the release candidates ISOs for the Ubuntu 9.10 release. Specifically, I tested Edubuntu. Edubuntu has since been discontinued but at the time it was an official Ubuntu flavor preloaded with lots of education apps. One of those education apps was Moodle, an e-learning platform.
When testing Moodle, I found that a default installation would make Moodle impossible to use locally. I figured out how to fix this issue. This was really exciting: I finally found an Ubuntu bug I knew how to fix. I filed the bug report.
This was very late in the Ubuntu 9.10 release process and Ubuntu was in the Final Freeze state. In Final Freeze, every upload to packages included in the default install need to be individually approved by a member of the Ubuntu Release Team. Also, I didn t have upload rights to Ubuntu. Jordan Mantha (LaserJock), an Edubuntu maintainer, sponsored my bug fix upload.
I also forwarded my patch to Debian.
While trying to figure out what wasn t working with Moodle, I stumbled across a packaging bug. Edubuntu provided a choice of MySQL or PostgreSQL for the system default database. MySQL was the default, but if PostgreSQL were chosen instead, Moodle wouldn t work. I figured out how to fix this bug too a week later. Jordan sponsored this upload and Steve Langasek from the Release Team approved it so it also was able to be fixed before 9.10 was released.
Although the first bug was new to 9.10 because of a behavior change in a low-level dependency, this PostgreSQL bug existed in stable Ubuntu releases. Therefore, I prepared Stable Release Updates for Ubuntu 9.04 and Ubuntu 8.04 LTS.
Afterwards
Six months later, I was able to attend my first Ubuntu Developer Summit. I was living in Bahrain (in the Middle East) at the time and a trip to Belgium seemed easier to me than if I were living in the United States where I usually live. This was the Ubuntu Developer Summit where planning for Ubuntu 10.10 took place. I like to believe that I helped with the naming since I addedMaverick to the wiki page where people contribute suggestions.
I did not apply for financial sponsorship to attend and I stayed in a budget hotel on the other side of Brussels. The event venue was on the outskirts of Brussels so there wasn t a direct bus or metro line to get there. I rented a car. I didn t yet have a smartphone and I had a LOT of trouble navigating to and from the site every day. I learned then that it s best to stay close to the conference site since a lot of the event is actually in the unstructured time in the evenings. Fortunately, I managed to arrive in time for Mark Shuttleworth s keynote where the Unity desktop was first announced. This was released in Ubuntu 10.10 in the Ubuntu Netbook Remix and became the default for Ubuntu Desktop in Ubuntu 11.04.
Ubuntu s switch to Unity provided me with a huge opportunity. In April 2011, GNOME 3.0 was released. I wanted to try it but it wasn t yet packaged in Ubuntu or Debian. It was suggested that I could help work on packaging the major new version in a PPA. The PPA was convenient because I was able to get permission to upload there easier than being able to upload directly to Ubuntu. My contributions there then enabled me to get upload rights to the Ubuntu Desktop packages later that year.
At a later Ubuntu Developer Summit, it was suggested that I start an official Ubuntu flavor for GNOME. So along with Tim Lunn (darkxst), I co-founded Ubuntu GNOME. Years later, Canonical stopped actively developing Unity; instead, Ubuntu GNOME was merged into Ubuntu Desktop.
Along the way, I became an Ubuntu Core Developer and a Debian Developer. And in January 2022, I joined Canonical on the Desktop Team. This all still feels amazing to me. It took me a long time to be comfortable calling myself a developer!
Conclusion
My first Ubuntu bugfix was 13 years ago this week. Because Ubuntu historically uses alphabetical adjective animal release names, 13 years means that we have rolled around to the letter K again! Later today, we begin release candidate ISO testing for Ubuntu 22.10 Kinetic Kudu .
I encourage you to help us test the release candidates and report bugs that you find. If you figure out how to fix a bug, we still sponsor bug fixes. If you are an Ubuntu contributor, I highly encourage you to attend an Ubuntu Summit if you can. The first Ubuntu Summit in years will be in 3 weeks in Prague, but the intent is for the Ubuntu Summits to be recurring events again.
I work on OpenJDK backports:
taking a patch that was committed to a current version of JDK, and adapting it
to an older one. There are four main OpenJDK versions that I am concerned with:
the current version ("jdk"), 8, 11 and 17. These are all maintained in separate
Git(Hub) repositories.
It's very useful to have access to the other JDKs when working on any
particular version. For example, to backport a patch from the latest version to
17, where the delta is not too big, a lot of the time you can cherry-pick the
patch unmodified. To do git cherry-pick <some-commit> in a git repository
tracking JDK17, where <some-commit> is in "jdk", I need the "jdk" repository
configured as a remote for my local jdk17 repository.
Maintaining completely separate local git repositories for all four JDK versions,
with each of them having a subset of the others added as remotes, adds up to a
lot of duplicated data on local storage.
For a little while I was exploring using shared clones: a local clone of another local git
repository which share some local metadata. This saves on some disc space, but
it does not share the configuration for remotes: so I still have to add any other
JDK versions I want as remotes in each shared clone (even if the underlying objects
already exist in the shared metadata)
Then I discovered git worktree. The
git repositories that I've used up until now have had exactly zero (for a bare
clone) or one worktree: in other words, the check-out, the actual source code
files. Git does actually support having more than one worktree, which can be
achieved like so:
The result (in this example) is a new checkout, in this case of a new local
branch named jdk8u-master at the sibling directory path jdk.worktree.jdk8u,
tracking the remote branch jdk8u-dev/master. Within that checkout, there is a
file .git which contains a pointer to (indirectly) the main local repository
path:
The directory itself behaves exactly like the real one, in that I can see all
the configured remotes, and other checked out branches in other worktree
paths:
Above, you can see that the current worktree is the branch 8237479-jdk8u-dev,
marked (as usual) by the prefix *, and two other branches are checked out
in other worktrees, marked by the prefix +.
I only need to configure one local git repository with all of the remotes
I am concerned about; I can inspect, compare, cherry-pick, check out, etc.
any objects from any of those branches from any of my work trees; there's
only one .git directory with all the configuration and storage for the
git blobs across all the versions.
Well this is a mouthful.
I recently worked on a neat hack called puppet-package-check. It
is designed to warn about manually installed packages, to make sure
"everything is in Puppet". But it turns out it can (probably?)
dramatically decrease the bootstrap time of Puppet bootstrap when it
needs to install a large number of packages.
Detecting manual packages
On a cleanly filed workstation, it looks like this:
Yuck! That's a lot of shit to go through.
Notice how the packages get sorted between "old" and "new"
packages. This is because popcon is used as a tool to mark which
packages are "old". If you have unmanaged packages, the "old" ones are
likely things that you can uninstall, for example.
If you don't have popcon installed, you'll also get this warning:
popcon stats not available: [Errno 2] No such file or directory: '/var/log/popularity-contest'
The error can otherwise be safely ignored, but you won't get "help"
prioritizing the packages to add to your manifests.
Note that the tool ignores packages that were "marked" (see
apt-mark(8)) as automatically installed. This implies that you
might have to do a little bit of cleanup the first time you run this,
as Debian doesn't necessarily mark all of those packages correctly on
first install. For example, here's how it looks like on a clean
install, after Puppet ran:
Normally, there should be unmanaged packages here. But because of the
way Debian is installed, a lot of libraries and some core packages are
marked as manually installed, and are of course not managed through
Puppet. There are two solutions to this problem:
really manage everything in Puppet (argh)
mark packages as automatically installed
I typically chose the second path and mark a ton of stuff as
automatic. Then either they will be auto-removed, or will stop being
listed. In the above scenario, one could mark all libraries as
automatically installed with:
apt-mark auto $(./bin/puppet-package-check grep -o 'lib[^ ]*')
... but if you trust that most of that stuff is actually garbage that
you don't really want installed anyways, you could just mark it all
as automatically installed:
apt-mark auto $(./bin/puppet-package-check)
In my case, that ended up keeping basically all libraries (because of
course they're installed for some reason) and auto-removing this:
You'll notice xorg in there: yep, that's bad. Not what I wanted. But
for some reason, on other workstations, I did not actually have
xorg installed. Turns out having xserver-xorg is enough, and that
one has dependencies. So now I guess I just learned to stop worrying
and live without X(org).
Optimizing large package installs
But that, of course, is not all. Why make things simple when you can
have an unreadable title that is trying to be both syntactically
correct and click-baity enough to flatter my vain ego? Right.
One of the challenges in bootstrapping Puppet with large package lists
is that it's slow. Puppet lists packages as individual resources and
will basically run apt install $PKG on every package in the
manifest, one at a time. While the overhead of apt is generally
small, when you add things like apt-listbugs, apt-listchanges,
needrestart, triggers and so on, it can take forever setting up a
new host.
So for initial installs, it can actually makes sense to skip the queue
and just install everything in one big batch.
And because the above tool inspects the packages installed by Puppet,
you can run it against a catalog and have a full lists of all the
packages Puppet would install, even before I even had Puppet
running.
So when reinstalling my laptop, I basically did this:
That massive grep was because there are currently a lot of
packages missing from bookworm. Those are all packages that I have
in my catalog but that still haven't made it to bookworm. Sad, I
know. I eventually worked around that by adding bullseye sources so
that the Puppet manifest actually ran.
The point here is that this improves the Puppet run time a lot. All
packages get installed at once, and you get a nice progress bar. Then
you actually run Puppet to deploy configurations and all the other
goodies:
puppet agent --test
I wish I could tell you how much faster that ran. I don't know, and I
will not go through a full reinstall just to please your
curiosity. The only hard number I have is that it installed 444
packages (which exploded in 10,191 packages with dependencies) in a
mere 10 minutes. That might also be with the packages already
downloaded.
In any case, I have that gut feeling it's faster, so you'll have to
just trust my gut. It is, after all, much more important than you
might think.
It figures out what you ve done manually, stores it locally in a Git
repository, generates code that s able to recreate your efforts, and
helps you deploy those changes to production
That tool has unfortunately been abandoned for a decade at this point.
Also note that the AutoRemove::RecommendsImportant and
AutoRemove::SuggestsImportant are relevant here. If it is set to
true (the default), a package will not be removed if it is
(respectively) a Recommends or Suggests of another package (as
opposed to the normal Depends). In other words, if you want to also
auto-remove packages that are only Suggests, you would, for example,
add this to apt.conf:
AutoRemove::SuggestsImportant false;
Paul Wise has tried to make the Debian installer and debootstrap
properly mark packages as automatically installed in the past, but his
bug reports were rejected. The other suggestions in this section are
also from Paul, thanks!
Our local Debian user group gathered on Sunday August 28th1 at the very
hackish Foulab for the August 2022 edition of our "Debian & Stuff"
meetings.
As always, the event was a success and we had lots of fun. Nine people showed
up, including some new faces and people I hadn't seen in a while:
On my side, although I was badly sleep-deprived 2, I still managed to be
somewhat productive!
One of the WiFi Access Points we use in our 4-apartment LAN had been
boot-looping for a few weeks, after a failed sysupgrade to the latest version
of OpenWRT. lavamind and I suspect the flash got corrupted in a way or another
during the upgrade process...
Lucky for us, this model has a serial port and runs U-Boot. After a
bit of tinkering, some electrical tape and two different serial
adapters3, we managed to identify the pin layout and got a shell on the
machine. The device has a reset button, but since the kernel panic was
happening too soon in the boot process, we weren't able to get into OpenWRT's
failsafe mode this way.
Once we had serial access, wiping the flash and re-installing OpenWRT fixed our
problem. A quick ansible-playbook run later, the device was back to being
usable and configured :)
I was too tired to keep track of what others did, but I took some nice pictures
of the pizza we got, and of this nice blow-up Tux wearing a Foulab t-shirt. Enjoy!
As always, thanks to the Debian project for granting us a budget to rent the
venue and to buy some food.
Please excuse the late blog post, it's Harvest Season here and I've been
quite busy.
A bad case of wry neck kept me from sleeping properly for a while in
August.
As it turns out, serial connections work better when you use the
right pins for TX and RX!
History
Before I start, the game I was talking about is called Cell To Singularity. Now I haven t gone much in the game as I have shared but think that the Singularity it refers to is the Technological Singularity that people think will happen. Whether that will happen or not is open to debate to one and all. This is going to be a bit long one.
Confession Time :- When I was sharing in the blog post, I had no clue that we actually had sessions on it in this year s Debconf. I just saw the schedule yesterday and then came to know. Then I saw Guido s two talks, one at Debconf as well as one as Froscon. In fact, saw the Froscon talk first, and then the one at Debconf. Both the talks are nearly the same except for a thing here or a thing there.
Now because I was not there so my understanding and knowledge would be disadvantageously asymmetrical to Guido and others who were there and could talk and share more. Having a Debian mobile or Debian on the mobile could also make Debian more popular and connectable to the masses, one of the things that were not pointed out in the Debian India BOF sadly. At the same time, there are some facts that are not on the table and hence not thought about.
Being a B.Com person, I have been following not just the technical but also how the economics work and smartphone penetration in India is pretty low or historically been very low, say around 3-4% while the majority that people use, almost 90-95% of the market uses what are called non-smartphones or dumbphones. Especially during the pandemic and even after that the dumbphones market actually went up while smartphones stagnated and even came down. There is a lot of inventory at most of the dealers that they can t get rid of. From a dealer perspective, it probably makes more sense to buy and sell dumbphones more in number as the turnaround of capital is much faster and easier than for smartphones. I have seen people spend a number of hours and rightly so in order to make their minds up on a smartphone while for a dumbphone, it is a 10-minute thing. Ask around, figure out who is selling at the cheapest, and just buy. Most of these low-end phones are coming from China. In fact, even in the middle and getting even into smartphones, the Chinese are the masters from whom we buy, even as they have occupied Indian territory. In the top five, Samsung comes at number three of four (sharing about Samsung as a fan and having used them.) even though battery times are atrocious, especially with Android 12L. The only hope that most of the smartphone manufacturers have is lowering the sticker prices and hoping that 5G Adoption picks up and that is what they are betting on but that comes with its own share of drawbacks as can be seen.
GNOME, MATE, memory leaks, Payments
FWIW, while I do have GNOME and do use a couple of tools from the GNOME stack, I hate GNOME with a passion. I have been a mate user for almost a decade now and really love the simplicity that mate has vis-a-vis GNOME. And with each release, MATE has only become better. So, it would be nice if we can have MATE on the mobile phone. How adaptive the apps might be on the smaller area, I dunno. It would be interesting to find out if and how people are looking at debugging memory leaks on mobile phones. Although finding memory leaks on any platform is good, finding them and fixing them on a mobile phone is pretty much critical as most phones have fixed & relatively small amounts of memory and it is and can get quickly exhausted.
One of the things that were asked in the Q&A was about payments. The interesting thing is both UK and India are the same or markedly similar in regard as far as contactless payments being concerned. What most Indians have or use is basically UPI which is basically backed by your bank. Unlike in some other countries where you have a selection of wallets and even temporary/permanent virtual accounts whereby you can minimize your risks in case your mobile gets stolen or something, here we don t have that. There are three digital wallets that I know Paytm Not used (have heard it s creepy, but don t really know), Google pay (Unfortunately, this is the one I use, they bought multiple features, and in the last couple of years have really taken the game away from Paytm but also creepy.). The last one is Samsung Pay (haven t really used it as their find my phone app. always crashes, dunno how it is supposed to work.) But I do find that the apps. are vulnerable. Every day there is some or other news of fraud happening. Previously, only States like Bihar and Jharkhand used to be infamous for cybercrime as a hub, but now even States like Andhra Pradesh have joined and surpassed them :(. People have lost lakhs and crores, this is just a few days back. Some more info. on UPI can be found here and GitHub has a few implementation examples that anybody could look at and run away with it.
Balancing on three things
For any new mobile phone to crack the market, it has to balance three things. One, achieve economies of scale. Unless, that is not taken care of or done, however good or bad the product might be, it remains a niche and dies after some time. While Guido shared about Openmoko and N900, one of the more interesting bits from a user perspective at least was the OLPC project. There are many nuances that the short article didn t go through. While I can t say for other countries, at least in India, no education initiative happens without corruption. And perhaps Nicholas s hands were tied while other manufacturers would and could do to achieve their sales targets. In India, it flopped because there was no way for volunteers to buy or get OLPC unless they were part of a school or college. There was some traction in FOSS communities, but that died down once OLPC did the partnership with MS-Windows, and proverbially broke the camel s back. FWIW, I think the idea, the concept, and even the machine were far ahead of their time.
The other two legs are support and Warranty Without going into any details, I can share and tell there were quite a few OLPC type attempts using conventional laptops or using Android and FOSS or others or even using one of the mainstream distributions but the problems have always been polishing, training and support. Guido talked about privacy as a winning feature but fails to take into account that people want to know that their privacy isn t being violated. If a mobile phone answers to Hey Google does it mean it was passively gathering, storing, and sending info to third parties, we just don t know. The mobile phone could be part of the right to repair profile while at the same time it can force us to ask many questions about the way things currently are and going to be. Six months down the line all the flagships of all companies are working on being able to take and share through satellites (Satellite Internet) and perhaps maybe a few non-flagships. Of course, if you are going to use a satellite, then you are going to drain that much more quickly. In all and every event there are always gonna be tradeoffs.
The Debian-mobile mailing list doesn t seem to have many takers. The latest I could find there is written by Paul Wise. I am in a similar boat (Samsung; SM-M526B; Lahaina; arm64-v8a) v12. It is difficult to know which release would work on your machine, make sure that the building from the source is not tainted and pristine and needs a way to backup and restore if you need to. I even tried installing GNURoot Debian and the Xserver alternative they had shared but was unable to use the touch interface on the fakeroot instance . The system talks about a back key but what back key I have no clue.
Precursor Events Debconf 2023
As far as precursor events are concerned before Debconf 23 in India, all the festivals that we have could be used to showcase Debian. In fact, the ongoing Ganesh Chaturthi would have been the perfect way to showcase Debian and apps. according to the audience. Even the festival of Durga Puja, Diwali etc. can be used. When commercial organizations use the same festivals, why can t we? What perhaps we would need to figure out is the funding part as well as getting permissions from Municipal authorities. One of the things for e.g. that we could do is buy either a permanent 24 monitor or a 34 TV and use that to display Debian and apps. The bigger, the better. Something that we could use day to day and also is used for events. This would require significant amounts of energy so we could approach companies, small businesses and individuals both for volunteering as well as helping out with funding.
Somebody asked how we could do online stuff and why it is somewhat boring. What could be done for e.g. instead of 4-5 hrs. of things, break it into manageable 45 minute pieces. 4-5 hrs. is long and is gonna fatigue the best of people. Make it into 45-minute negotiable chunks, and intersphere it with jokes, hacks, anecdotes, and war stories. People do not like or want to be talked down to but rather converse. One of the things that I saw many of the artists do is have shows and limit the audience to 20-24 people on zoom call or whatever videoconferencing system you have and play with them. The passive audience enjoys the play between the standup guy and the crowd he works on, some of them may be known to him personally so he can push that envelope a bit more. The same thing can be applied here. Share the passion, and share why we are doing something. For e.g. you could do smem -t -k less and give a whole talk about how memory is used and freed during a session, how are things different on desktop and ARM as far as memory architecture is concerned (if there is). What is being done on the hardware side, what is on the software side and go on and on. Then share about troubleshooting applications. Valgrind is super slow and makes life hell, is there some better app ? Doesn t matter if you are a front-end or a back-end developer you need to know this and figure out the best way to deal with in your app/program. That would have lot of value. And this is just an e.g. to help trigger more ideas from the community. I am sure others probably have more fun ideas as to what can be done. I am stopping here now otherwise would just go on, till later. Feel free to comment, feedback. Hope it generates some more thinking and excitement on the grey cells.
Inspired by several others (such as Alex Schroeder s post and Szcze uja s prompt), as well as a desire to get this down for my kids, I figure it s time to write a bit about living through the PC and Internet revolution where I did: outside a tiny town in rural Kansas. And, as I ve been back in that same area for the past 15 years, I reflect some on the challenges that continue to play out.
Although the stories from the others were primarily about getting online, I want to start by setting some background. Those of you that didn t grow up in the same era as I did probably never realized that a typical business PC setup might cost $10,000 in today s dollars, for instance. So let me start with the background.
Nothing was easy
This story begins in the 1980s. Somewhere around my Kindergarten year of school, around 1985, my parents bought a TRS-80 Color Computer 2 (aka CoCo II). It had 64K of RAM and used a TV for display and sound.
This got you the computer. It didn t get you any disk drive or anything, no joysticks (required by a number of games). So whenever the system powered down, or it hung and you had to power cycle it a frequent event you d lose whatever you were doing and would have to re-enter the program, literally by typing it in.
The floppy drive for the CoCo II cost more than the computer, and it was quite common for people to buy the computer first and then the floppy drive later when they d saved up the money for that.
I particularly want to mention that computers then didn t come with a modem. What would be like buying a laptop or a tablet without wifi today. A modem, which I ll talk about in a bit, was another expensive accessory. To cobble together a system in the 80s that was capable of talking to others with persistent storage (floppy, or hard drive), screen, keyboard, and modem would be quite expensive. Adjusted for inflation, if you re talking a PC-style device (a clone of the IBM PC that ran DOS), this would easily be more expensive than the Macbook Pros of today.
Few people back in the 80s had a computer at home. And the portion of those that had even the capability to get online in a meaningful way was even smaller.
Eventually my parents bought a PC clone with 640K RAM and dual floppy drives. This was primarily used for my mom s work, but I did my best to take it over whenever possible. It ran DOS and, despite its monochrome screen, was generally a more capable machine than the CoCo II. For instance, it supported lowercase. (I m not even kidding; the CoCo II pretty much didn t.) A while later, they purchased a 32MB hard drive for it what luxury!
Just getting a machine to work wasn t easy. Say you d bought a PC, and then bought a hard drive, and a modem. You didn t just plug in the hard drive and it would work. You would have to fight it every step of the way. The BIOS and DOS partition tables of the day used a cylinder/head/sector method of addressing the drive, and various parts of that those addresses had too few bits to work with the big drives of the day above 20MB. So you would have to lie to the BIOS and fdisk in various ways, and sort of work out how to do it for each drive. For each peripheral serial port, sound card (in later years), etc., you d have to set jumpers for DMA and IRQs, hoping not to conflict with anything already in the system. Perhaps you can now start to see why USB and PCI were so welcomed.
Sharing and finding resources
Despite the two computers in our home, it wasn t as if software written on one machine just ran on another. A lot of software for PC clones assumed a CGA color display. The monochrome HGC in our PC wasn t particularly compatible. You could find a TSR program to emulate the CGA on the HGC, but it wasn t particularly stable, and there s only so much you can do when a program that assumes color displays on a monitor that can only show black, dark amber, or light amber.
So I d periodically get to use other computers most commonly at an office in the evening when it wasn t being used.
There were some local computer clubs that my dad took me to periodically. Software was swapped back then; disks copied, shareware exchanged, and so forth. For me, at least, there was no online to download software from, and selling software over the Internet wasn t a thing at all.
Three Different Worlds
There were sort of three different worlds of computing experience in the 80s:
Home users. Initially using a wide variety of software from Apple, Commodore, Tandy/RadioShack, etc., but eventually coming to be mostly dominated by IBM PC clones
Small and mid-sized business users. Some of them had larger minicomputers or small mainframes, but most that I had contact with by the early 90s were standardized on DOS-based PCs. More advanced ones had a network running Netware, most commonly. Networking hardware and software was generally too expensive for home users to use in the early days.
Universities and large institutions. These are the places that had the mainframes, the earliest implementations of TCP/IP, the earliest users of UUCP, and so forth.
The difference between the home computing experience and the large institution experience were vast. Not only in terms of dollars the large institution hardware could easily cost anywhere from tens of thousands to millions of dollars but also in terms of sheer resources required (large rooms, enormous power circuits, support staff, etc). Nothing was in common between them; not operating systems, not software, not experience. I was never much aware of the third category until the differences started to collapse in the mid-90s, and even then I only was exposed to it once the collapse was well underway.
You might say to me, Well, Google certainly isn t running what I m running at home! And, yes of course, it s different. But fundamentally, most large datacenters are running on x86_64 hardware, with Linux as the operating system, and a TCP/IP network. It s a different scale, obviously, but at a fundamental level, the hardware and operating system stack are pretty similar to what you can readily run at home. Back in the 80s and 90s, this wasn t the case. TCP/IP wasn t even available for DOS or Windows until much later, and when it was, it was a clunky beast that was difficult.
One of the things Kevin Driscoll highlights in his book called Modem World see my short post about it is that the history of the Internet we usually receive is focused on case 3: the large institutions. In reality, the Internet was and is literally a network of networks. Gateways to and from Internet existed from all three kinds of users for years, and while TCP/IP ultimately won the battle of the internetworking protocol, the other two streams of users also shaped the Internet as we now know it. Like many, I had no access to the large institution networks, but as I ve been reflecting on my experiences, I ve found a new appreciation for the way that those of us that grew up with primarily home PCs shaped the evolution of today s online world also.
An Era of Scarcity
I should take a moment to comment about the cost of software back then. A newspaper article from 1985 comments that WordPerfect, then the most powerful word processing program, sold for $495 (or $219 if you could score a mail order discount). That s $1360/$600 in 2022 money. Other popular software, such as Lotus 1-2-3, was up there as well. If you were to buy a new PC clone in the mid to late 80s, it would often cost $2000 in 1980s dollars. Now add a printer a low-end dot matrix for $300 or a laser for $1500 or even more. A modem: another $300. So the basic system would be $3600, or $9900 in 2022 dollars. If you wanted a nice printer, you re now pushing well over $10,000 in 2022 dollars.
You start to see one barrier here, and also why things like shareware and piracy if it was indeed even recognized as such were common in those days.
So you can see, from a home computer setup (TRS-80, Commodore C64, Apple ][, etc) to a business-class PC setup was an order of magnitude increase in cost. From there to the high-end minis/mainframes was another order of magnitude (at least!) increase. Eventually there was price pressure on the higher end and things all got better, which is probably why the non-DOS PCs lasted until the early 90s.
Increasing Capabilities
My first exposure to computers in school was in the 4th grade, when I would have been about 9. There was a single Apple ][ machine in that room. I primarily remember playing Oregon Trail on it. The next year, the school added a computer lab. Remember, this is a small rural area, so each graduating class might have about 25 people in it; this lab was shared by everyone in the K-8 building. It was full of some flavor of IBM PS/2 machines running DOS and Netware. There was a dedicated computer teacher too, though I think she was a regular teacher that was given somewhat minimal training on computers. We were going to learn typing that year, but I did so well on the very first typing program that we soon worked out that I could do programming instead. I started going to school early these machines were far more powerful than the XT at home and worked on programming projects there.
Eventually my parents bought me a Gateway 486SX/25 with a VGA monitor and hard drive. Wow! This was a whole different world. It may have come with Windows 3.0 or 3.1 on it, but I mainly remember running OS/2 on that machine. More on that below.
Programming
That CoCo II came with a BASIC interpreter in ROM. It came with a large manual, which served as a BASIC tutorial as well. The BASIC interpreter was also the shell, so literally you could not use the computer without at least a bit of BASIC.
Once I had access to a DOS machine, it also had a basic interpreter: GW-BASIC. There was a fair bit of software written in BASIC at the time, but most of the more advanced software wasn t. I wondered how these .EXE and .COM programs were written. I could find vague references to DEBUG.EXE, assemblers, and such. But it wasn t until I got a copy of Turbo Pascal that I was able to do that sort of thing myself. Eventually I got Borland C++ and taught myself C as well. A few years later, I wanted to try writing GUI programs for Windows, and bought Watcom C++ much cheaper than the competition, and it could target Windows, DOS (and I think even OS/2).
Notice that, aside from BASIC, none of this was free, and none of it was bundled. You couldn t just download a C compiler, or Python interpreter, or whatnot back then. You had to pay for the ability to write any kind of serious code on the computer you already owned.
The Microsoft Domination
Microsoft came to dominate the PC landscape, and then even the computing landscape as a whole. IBM very quickly lost control over the hardware side of PCs as Compaq and others made clones, but Microsoft has managed in varying degrees even to this day to keep a stranglehold on the software, and especially the operating system, side. Yes, there was occasional talk of things like DR-DOS, but by and large the dominant platform came to be the PC, and if you had a PC, you ran DOS (and later Windows) from Microsoft.
For awhile, it looked like IBM was going to challenge Microsoft on the operating system front; they had OS/2, and when I switched to it sometime around the version 2.1 era in 1993, it was unquestionably more advanced technically than the consumer-grade Windows from Microsoft at the time. It had Internet support baked in, could run most DOS and Windows programs, and had introduced a replacement for the by-then terrible FAT filesystem: HPFS, in 1988. Microsoft wouldn t introduce a better filesystem for its consumer operating systems until Windows XP in 2001, 13 years later. But more on that story later.
Free Software, Shareware, and Commercial Software
I ve covered the high cost of software already. Obviously $500 software wasn t going to sell in the home market. So what did we have?
Mainly, these things:
Public domain software. It was free to use, and if implemented in BASIC, probably had source code with it too.
Shareware
Commercial software (some of it from small publishers was a lot cheaper than $500)
Let s talk about shareware. The idea with shareware was that a company would release a useful program, sometimes limited. You were encouraged to register , or pay for, it if you liked it and used it. And, regardless of whether you registered it or not, were told please copy! Sometimes shareware was fully functional, and registering it got you nothing more than printed manuals and an easy conscience (guilt trips for not registering weren t necessarily very subtle). Sometimes unregistered shareware would have a nag screen a delay of a few seconds while they told you to register. Sometimes they d be limited in some way; you d get more features if you registered. With games, it was popular to have a trilogy, and release the first episode inevitably ending with a cliffhanger as shareware, and the subsequent episodes would require registration. In any event, a lot of software people used in the 80s and 90s was shareware. Also pirated commercial software, though in the earlier days of computing, I think some people didn t even know the difference.
Notice what s missing: Free Software / FLOSS in the Richard Stallman sense of the word. Stallman lived in the big institution world after all, he worked at MIT and what he was doing with the Free Software Foundation and GNU project beginning in 1983 never really filtered into the DOS/Windows world at the time. I had no awareness of it even existing until into the 90s, when I first started getting some hints of it as a port of gcc became available for OS/2. The Internet was what really brought this home, but I m getting ahead of myself.
I want to say again: FLOSS never really entered the DOS and Windows 3.x ecosystems. You d see it make a few inroads here and there in later versions of Windows, and moreso now that Microsoft has been sort of forced to accept it, but still, reflect on its legacy. What is the software market like in Windows compared to Linux, even today?
Now it is, finally, time to talk about connectivity!
Getting On-Line
What does it even mean to get on line? Certainly not connecting to a wifi access point. The answer is, unsurprisingly, complex. But for everyone except the large institutional users, it begins with a telephone.
The telephone system
By the 80s, there was one communication network that already reached into nearly every home in America: the phone system. Virtually every household (note I don t say every person) was uniquely identified by a 10-digit phone number. You could, at least in theory, call up virtually any other phone in the country and be connected in less than a minute.
But I ve got to talk about cost. The way things worked in the USA, you paid a monthly fee for a phone line. Included in that monthly fee was unlimited local calling. What is a local call? That was an extremely complex question. Generally it meant, roughly, calling within your city. But of course, as you deal with things like suburbs and cities growing into each other (eg, the Dallas-Ft. Worth metroplex), things got complicated fast. But let s just say for simplicity you could call others in your city.
What about calling people not in your city? That was long distance , and you paid often hugely by the minute for it. Long distance rates were difficult to figure out, but were generally most expensive during business hours and cheapest at night or on weekends. Prices eventually started to come down when competition was introduced for long distance carriers, but even then you often were stuck with a single carrier for long distance calls outside your city but within your state. Anyhow, let s just leave it at this: local calls were virtually free, and long distance calls were extremely expensive.
Getting a modem
I remember getting a modem that ran at either 1200bps or 2400bps. Either way, quite slow; you could often read even plain text faster than the modem could display it. But what was a modem?
A modem hooked up to a computer with a serial cable, and to the phone system. By the time I got one, modems could automatically dial and answer. You would send a command like ATDT5551212 and it would dial 555-1212. Modems had speakers, because often things wouldn t work right, and the telephone system was oriented around speech, so you could hear what was happening. You d hear it wait for dial tone, then dial, then hopefully the remote end would ring, a modem there would answer, you d hear the screeching of a handshake, and eventually your terminal would say CONNECT 2400. Now your computer was bridged to the other; anything going out your serial port was encoded as sound by your modem and decoded at the other end, and vice-versa.
But what, exactly, was the other end?
It might have been another person at their computer. Turn on local echo, and you can see what they did. Maybe you d send files to each other. But in my case, the answer was different: PC Magazine.
PC Magazine and CompuServe
Starting around 1986 (so I would have been about 6 years old), I got to read PC Magazine. My dad would bring copies that were being discarded at his office home for me to read, and I think eventually bought me a subscription directly. This was not just a standard magazine; it ran something like 350-400 pages an issue, and came out every other week. This thing was a monster. It had reviews of hardware and software, descriptions of upcoming technologies, pages and pages of ads (that often had some degree of being informative to them). And they had sections on programming. Many issues would talk about BASIC or Pascal programming, and there d be a utility in most issues. What do I mean by a utility in most issues ? Did they include a floppy disk with software?
No, of course not. There was a literal program listing printed in the magazine. If you wanted the utility, you had to type it in. And a lot of them were written in assembler, so you had to have an assembler. An assembler, of course, was not free and I didn t have one. Or maybe they wrote it in Microsoft C, and I had Borland C, and (of course) they weren t compatible. Sometimes they would list the program sort of in binary: line after line of a BASIC program, with lines like 64, 193, 253, 0, 53, 0, 87 that you would type in for hours, hopefully correctly. Running the BASIC program would, if you got it correct, emit a .COM file that you could then run. They did have a rudimentary checksum system built in, but it wasn t even a CRC, so something like swapping two numbers you d never notice except when the program would mysteriously hang.
Eventually they teamed up with CompuServe to offer a limited slice of CompuServe for the purpose of downloading PC Magazine utilities. This was called PC MagNet. I am foggy on the details, but I believe that for a time you could connect to the limited PC MagNet part of CompuServe for free (after the cost of the long-distance call, that is) rather than paying for CompuServe itself (because, OF COURSE, that also charged you per the minute.) So in the early days, I would get special permission from my parents to place a long distance call, and after some nerve-wracking minutes in which we were aware every minute was racking up charges, I could navigate the menus, download what I wanted, and log off immediately.
I still, incidentally, mourn what PC Magazine became. As with computing generally, it followed the mass market. It lost its deep technical chops, cut its programming columns, stopped talking about things like how SCSI worked, and so forth. By the time it stopped printing in 2009, it was no longer a square-bound 400-page beheamoth, but rather looked more like a copy of Newsweek, but with less depth.
Continuing with CompuServe
CompuServe was a much larger service than just PC MagNet. Eventually, our family got a subscription. It was still an expensive and scarce resource; I d call it only after hours when the long-distance rates were cheapest. Everyone had a numerical username separated by commas; mine was 71510,1421. CompuServe had forums, and files. Eventually I would use TapCIS to queue up things I wanted to do offline, to minimize phone usage online.
CompuServe eventually added a gateway to the Internet. For the sum of somewhere around $1 a message, you could send or receive an email from someone with an Internet email address! I remember the thrill of one time, as a kid of probably 11 years, sending a message to one of the editors of PC Magazine and getting a kind, if brief, reply back!
But inevitably I had
The Godzilla Phone Bill
Yes, one month I became lax in tracking my time online. I ran up my parents phone bill. I don t remember how high, but I remember it was hundreds of dollars, a hefty sum at the time. As I watched Jason Scott s BBS Documentary, I realized how common an experience this was. I think this was the end of CompuServe for me for awhile.
Toll-Free Numbers
I lived near a town with a population of 500. Not even IN town, but near town. The calling area included another town with a population of maybe 1500, so all told, there were maybe 2000 people total I could talk to with a local call though far fewer numbers, because remember, telephones were allocated by the household. There was, as far as I know, zero modems that were a local call (aside from one that belonged to a friend I met in around 1992). So basically everything was long-distance.
But there was a special feature of the telephone network: toll-free numbers. Normally when calling long-distance, you, the caller, paid the bill. But with a toll-free number, beginning with 1-800, the recipient paid the bill. These numbers almost inevitably belonged to corporations that wanted to make it easy for people to call. Sales and ordering lines, for instance. Some of these companies started to set up modems on toll-free numbers. There were few of these, but they existed, so of course I had to try them!
One of them was a company called PennyWise that sold office supplies. They had a toll-free line you could call with a modem to order stuff. Yes, online ordering before the web! I loved office supplies. And, because I lived far from a big city, if the local K-Mart didn t have it, I probably couldn t get it. Of course, the interface was entirely text, but you could search for products and place orders with the modem. I had loads of fun exploring the system, and actually ordered things from them and probably actually saved money doing so. With the first order they shipped a monster full-color catalog. That thing must have been 500 pages, like the Sears catalogs of the day. Every item had a part number, which streamlined ordering through the modem.
Inbound FAXes
By the 90s, a number of modems became able to send and receive FAXes as well. For those that don t know, a FAX machine was essentially a special modem. It would scan a page and digitally transmit it over the phone system, where it would at least in the early days be printed out in real time (because the machines didn t have the memory to store an entire page as an image). Eventually, PC modems integrated FAX capabilities.
There still wasn t anything useful I could do locally, but there were ways I could get other companies to FAX something to me. I remember two of them.
One was for US Robotics. They had an on demand FAX system. You d call up a toll-free number, which was an automated IVR system. You could navigate through it and select various documents of interest to you: spec sheets and the like. You d key in your FAX number, hang up, and US Robotics would call YOU and FAX you the documents you wanted. Yes! I was talking to a computer (of a sorts) at no cost to me!
The New York Times also ran a service for awhile called TimesFax. Every day, they would FAX out a page or two of summaries of the day s top stories. This was pretty cool in an era in which I had no other way to access anything from the New York Times. I managed to sign up for TimesFax I have no idea how, anymore and for awhile I would get a daily FAX of their top stories. When my family got its first laser printer, I could them even print these FAXes complete with the gothic New York Times masthead. Wow! (OK, so technically I could print it on a dot-matrix printer also, but graphics on a 9-pin dot matrix is a kind of pain that is a whole other article.)
My own phone line
Remember how I discussed that phone lines were allocated per household? This was a problem for a lot of reasons:
Anybody that tried to call my family while I was using my modem would get a busy signal (unable to complete the call)
If anybody in the house picked up the phone while I was using it, that would degrade the quality of the ongoing call and either mess up or disconnect the call in progress. In many cases, that could cancel a file transfer (which wasn t necessarily easy or possible to resume), prompting howls of annoyance from me.
Generally we all had to work around each other
So eventually I found various small jobs and used the money I made to pay for my own phone line and my own long distance costs. Eventually I upgraded to a 28.8Kbps US Robotics Courier modem even! Yes, you heard it right: I got a job and a bank account so I could have a phone line and a faster modem. Uh, isn t that why every teenager gets a job?
Now my local friend and I could call each other freely at least on my end (I can t remember if he had his own phone line too). We could exchange files using HS/Link, which had the added benefit of allowing split-screen chat even while a file transfer is in progress. I m sure we spent hours chatting to each other keyboard-to-keyboard while sharing files with each other.
Technology in Schools
By this point in the story, we re in the late 80s and early 90s. I m still using PC-style OSs at home; OS/2 in the later years of this period, DOS or maybe a bit of Windows in the earlier years. I mentioned that they let me work on programming at school starting in 5th grade. It was soon apparent that I knew more about computers than anybody on staff, and I started getting pulled out of class to help teachers or administrators with vexing school problems. This continued until I graduated from high school, incidentally often to my enjoyment, and the annoyance of one particular teacher who, I must say, I was fine with annoying in this way.
That s not to say that there was institutional support for what I was doing. It was, after all, a small school. Larger schools might have introduced BASIC or maybe Logo in high school. But I had already taught myself BASIC, Pascal, and C by the time I was somewhere around 12 years old. So I wouldn t have had any use for that anyhow.
There were programming contests occasionally held in the area. Schools would send teams. My school didn t really send anybody, but I went as an individual. One of them was run by a local college (but for jr. high or high school students. Years later, I met one of the professors that ran it. He remembered me, and that day, better than I did. The programming contest had problems one could solve in BASIC or Logo. I knew nothing about what to expect going into it, but I had lugged my computer and screen along, and asked him, Can I write my solutions in C? He was, apparently, stunned, but said sure, go for it. I took first place that day, leading to some rather confused teams from much larger schools.
The Netware network that the school had was, as these generally were, itself isolated. There was no link to the Internet or anything like it. Several schools across three local counties eventually invested in a fiber-optic network linking them together. This built a larger, but still closed, network. Its primary purpose was to allow students to be exposed to a wider variety of classes at high schools. Participating schools had an ITV room , outfitted with cameras and mics. So students at any school could take classes offered over ITV at other schools. For instance, only my school taught German classes, so people at any of those participating schools could take German. It was an early Zoom room. But alongside the TV signal, there was enough bandwidth to run some Netware frames. By about 1995 or so, this let one of the schools purchase some CD-ROM software that was made available on a file server and could be accessed by any participating school. Nice! But Netware was mainly about file and printer sharing; there wasn t even a facility like email, at least not on our deployment.
BBSs
My last hop before the Internet was the BBS. A BBS was a computer program, usually ran by a hobbyist like me, on a computer with a modem connected. Callers would call it up, and they d interact with the BBS. Most BBSs had discussion groups like forums and file areas. Some also had games. I, of course, continued to have that most vexing of problems: they were all long-distance.
There were some ways to help with that, chiefly QWK and BlueWave. These, somewhat like TapCIS in the CompuServe days, let me download new message posts for reading offline, and queue up my own messages to send later. QWK and BlueWave didn t help with file downloading, though.
BBSs get networked
BBSs were an interesting thing. You d call up one, and inevitably somewhere in the file area would be a BBS list. Download the BBS list and you ve suddenly got a list of phone numbers to try calling. All of them were long distance, of course. You d try calling them at random and have a success rate of maybe 20%. The other 80% would be defunct; you might get the dreaded this number is no longer in service or the even more dreaded angry human answering the phone (and of course a modem can t talk to a human, so they d just get silence for probably the nth time that week). The phone company cared nothing about BBSs and recycled their numbers just as fast as any others.
To talk to various people, or participate in certain discussion groups, you d have to call specific BBSs. That s annoying enough in the general case, but even more so for someone paying long distance for it all, because it takes a few minutes to establish a connection to a BBS: handshaking, logging in, menu navigation, etc.
But BBSs started talking to each other. The earliest successful such effort was FidoNet, and for the duration of the BBS era, it remained by far the largest. FidoNet was analogous to the UUCP that the institutional users had, but ran on the much cheaper PC hardware. Basically, BBSs that participated in FidoNet would relay email, forum posts, and files between themselves overnight. Eventually, as with UUCP, by hopping through this network, messages could reach around the globe, and forums could have worldwide participation asynchronously, long before they could link to each other directly via the Internet. It was almost entirely volunteer-run.
Running my own BBS
At age 13, I eventually chose to set up my own BBS. It ran on my single phone line, so of course when I was dialing up something else, nobody could dial up me. Not that this was a huge problem; in my town of 500, I probably had a good 1 or 2 regular callers in the beginning.
In the PC era, there was a big difference between a server and a client. Server-class software was expensive and rare. Maybe in later years you had an email client, but an email server would be completely unavailable to you as a home user. But with a BBS, I could effectively run a server. I even ran serial lines in our house so that the BBS could be connected from other rooms! Since I was running OS/2, the BBS didn t tie up the computer; I could continue using it for other things.
FidoNet had an Internet email gateway. This one, unlike CompuServe s, was free. Once I had a BBS on FidoNet, you could reach me from the Internet using the FidoNet address. This didn t support attachments, but then email of the day didn t really, either.
Various others outside Kansas ran FidoNet distribution points. I believe one of them was mgmtsys; my memory is quite vague, but I think they offered a direct gateway and I would call them to pick up Internet mail via FidoNet protocols, but I m not at all certain of this.
Pros and Cons of the Non-Microsoft World
As mentioned, Microsoft was and is the dominant operating system vendor for PCs. But I left that world in 1993, and here, nearly 30 years later, have never really returned. I got an operating system with more technical capabilities than the DOS and Windows of the day, but the tradeoff was a much smaller software ecosystem. OS/2 could run DOS programs, but it ran OS/2 programs a lot better. So if I were to run a BBS, I wanted one that had a native OS/2 version limiting me to a small fraction of available BBS server software. On the other hand, as a fully 32-bit operating system, there started to be OS/2 ports of certain software with a Unix heritage; most notably for me at the time, gcc. At some point, I eventually came across the RMS essays and started to be hooked.
Internet: The Hunt Begins
I certainly was aware that the Internet was out there and interesting. But the first problem was: how the heck do I get connected to the Internet?
Learning Link and Gopher
ISPs weren t really a thing; the first one in my area (though still a long-distance call) started in, I think, 1994. One service that one of my teachers got me hooked up with was Learning Link. Learning Link was a nationwide collaboration of PBS stations and schools, designed to build on the educational mission of PBS. The nearest Learning Link station was more than a 3-hour drive away but critically, they had a toll-free access number, and my teacher convinced them to let me use it. I connected via a terminal program and a modem, like with most other things. I don t remember much about it, but I do remember a very important thing it had: Gopher. That was my first experience with Gopher.
Learning Link was hosted by a Unix derivative (Xenix), but it didn t exactly give everyone a shell. I seem to recall it didn t have open FTP access either. The Gopher client had FTP access at some point; I don t recall for sure if it did then. If it did, then when a Gopher server referred to an FTP server, I could get to it. (I am unclear at this point if I could key in an arbitrary FTP location, or knew how, at that time.) I also had email access there, but I don t recall exactly how; probably Pine. If that s correct, that would have dated my Learning Link access as no earlier than 1992.
I think my access time to Learning Link was limited. And, since the only way to get out on the Internet from there was Gopher and Pine, I was somewhat limited in terms of technology as well. I believe that telnet services, for instance, weren t available to me.
Computer labs
There was one place that tended to have Internet access: colleges and universities. In 7th grade, I participated in a program that resulted in me being invited to visit Duke University, and in 8th grade, I participated in National History Day, resulting in a trip to visit the University of Maryland. I probably sought out computer labs at both of those. My most distinct memory was finding my way into a computer lab at one of those universities, and it was full of NeXT workstations. I had never seen or used NeXT before, and had no idea how to operate it. I had brought a box of floppy disks, unaware that the DOS disks probably weren t compatible with NeXT.
Closer to home, a small college had a computer lab that I could also visit. I would go there in summer or when it wasn t used with my stack of floppies. I remember downloading disk images of FLOSS operating systems: FreeBSD, Slackware, or Debian, at the time. The hash marks from the DOS-based FTP client would creep across the screen as the 1.44MB disk images would slowly download. telnet was also available on those machines, so I could telnet to things like public-access Archie servers and libraries though not Gopher. Still, FTP and telnet access opened up a lot, and I learned quite a bit in those years.
Continuing the Journey
At some point, I got a copy of the Whole Internet User s Guide and Catalog, published in 1994. I still have it. If it hadn t already figured it out by then, I certainly became aware from it that Unix was the dominant operating system on the Internet. The examples in Whole Internet covered FTP, telnet, gopher all assuming the user somehow got to a Unix prompt. The web was introduced about 300 pages in; clearly viewed as something that wasn t page 1 material. And it covered the command-line www client before introducing the graphical Mosaic. Even then, though, the book highlighted Mosaic s utility as a front-end for Gopher and FTP, and even the ability to launch telnet sessions by clicking on links. But having a copy of the book didn t equate to having any way to run Mosaic. The machines in the computer lab I mentioned above all ran DOS and were incapable of running a graphical browser. I had no SLIP or PPP (both ways to run Internet traffic over a modem) connectivity at home. In short, the Web was something for the large institutional users at the time.
CD-ROMs
As CD-ROMs came out, with their huge (for the day) 650MB capacity, various companies started collecting software that could be downloaded on the Internet and selling it on CD-ROM. The two most popular ones were Walnut Creek CD-ROM and Infomagic. One could buy extensive Shareware and gaming collections, and then even entire Linux and BSD distributions. Although not exactly an Internet service per se, it was a way of bringing what may ordinarily only be accessible to institutional users into the home computer realm.
Free Software Jumps In
As I mentioned, by the mid 90s, I had come across RMS s writings about free software most probably his 1992 essay Why Software Should Be Free. (Please note, this is not a commentary on the more recently-revealed issues surrounding RMS, but rather his writings and work as I encountered them in the 90s.) The notion of a Free operating system not just in cost but in openness was incredibly appealing. Not only could I tinker with it to a much greater extent due to having source for everything, but it included so much software that I d otherwise have to pay for. Compilers! Interpreters! Editors! Terminal emulators! And, especially, server software of all sorts. There d be no way I could afford or run Netware, but with a Free Unixy operating system, I could do all that. My interest was obviously piqued. Add to that the fact that I could actually participate and contribute I was about to become hooked on something that I ve stayed hooked on for decades.
But then the question was: which Free operating system? Eventually I chose FreeBSD to begin with; that would have been sometime in 1995. I don t recall the exact reasons for that. I remember downloading Slackware install floppies, and probably the fact that Debian wasn t yet at 1.0 scared me off for a time. FreeBSD s fantastic Handbook far better than anything I could find for Linux at the time was no doubt also a factor.
The de Raadt Factor
Why not NetBSD or OpenBSD? The short answer is Theo de Raadt. Somewhere in this time, when I was somewhere between 14 and 16 years old, I asked some questions comparing NetBSD to the other two free BSDs. This was on a NetBSD mailing list, but for some reason Theo saw it and got a flame war going, which CC d me. Now keep in mind that even if NetBSD had a web presence at the time, it would have been minimal, and I would have not all that unusually for the time had no way to access it. I was certainly not aware of the, shall we say, acrimony between Theo and NetBSD. While I had certainly seen an online flamewar before, this took on a different and more disturbing tone; months later, Theo randomly emailed me under the subject SLIME saying that I was, well, SLIME . I seem to recall periodic emails from him thereafter reminding me that he hates me and that he had blocked me. (Disclaimer: I have poor email archives from this period, so the full details are lost to me, but I believe I am accurately conveying these events from over 25 years ago)
This was a surprise, and an unpleasant one. I was trying to learn, and while it is possible I didn t understand some aspect or other of netiquette (or Theo s personal hatred of NetBSD) at the time, still that is not a reason to flame a 16-year-old (though he would have had no way to know my age). This didn t leave any kind of scar, but did leave a lasting impression; to this day, I am particularly concerned with how FLOSS projects handle poisonous people. Debian, for instance, has come a long way in this over the years, and even Linus Torvalds has turned over a new leaf. I don t know if Theo has.
In any case, I didn t use NetBSD then. I did try it periodically in the years since, but never found it compelling enough to justify a large switch from Debian. I never tried OpenBSD for various reasons, but one of them was that I didn t want to join a community that tolerates behavior such as Theo s from its leader.
Moving to FreeBSD
Moving from OS/2 to FreeBSD was final. That is, I didn t have enough hard drive space to keep both. I also didn t have the backup capacity to back up OS/2 completely. My BBS, which ran Virtual BBS (and at some point also AdeptXBBS) was deleted and reincarnated in a different form. My BBS was a member of both FidoNet and VirtualNet; the latter was specific to VBBS, and had to be dropped. I believe I may have also had to drop the FidoNet link for a time. This was the biggest change of computing in my life to that point. The earlier experiences hadn t literally destroyed what came before. OS/2 could still run my DOS programs. Its command shell was quite DOS-like. It ran Windows programs. I was going to throw all that away and leap into the unknown.
I wish I had saved a copy of my BBS; I would love to see the messages I exchanged back then, or see its menu screens again. I have little memory of what it looked like. But other than that, I have no regrets. Pursuing Free, Unixy operating systems brought me a lot of enjoyment and a good career.
That s not to say it was easy. All the problems of not being in the Microsoft ecosystem were magnified under FreeBSD and Linux. In a day before EDID, monitor timings had to be calculated manually and you risked destroying your monitor if you got them wrong. Word processing and spreadsheet software was pretty much not there for FreeBSD or Linux at the time; I was therefore forced to learn LaTeX and actually appreciated that. Software like PageMaker or CorelDraw was certainly nowhere to be found for those free operating systems either. But I got a ton of new capabilities.
I mentioned the BBS didn t shut down, and indeed it didn t. I ran what was surely a supremely unique oddity: a free, dialin Unix shell server in the middle of a small town in Kansas. I m sure I provided things such as pine for email and some help text and maybe even printouts for how to use it. The set of callers slowly grew over the time period, in fact.
And then I got UUCP.
Enter UUCP
Even throughout all this, there was no local Internet provider and things were still long distance. I had Internet Email access via assorted strange routes, but they were all strange. And, I wanted access to Usenet. In 1995, it happened.
The local ISP I mentioned offered UUCP access. Though I couldn t afford the dialup shell (or later, SLIP/PPP) that they offered due to long-distance costs, UUCP s very efficient batched processes looked doable. I believe I established that link when I was 15, so in 1995.
I worked to register my domain, complete.org, as well. At the time, the process was a bit lengthy and involved downloading a text file form, filling it out in a precise way, sending it to InterNIC, and probably mailing them a check. Well I did that, and in September of 1995, complete.org became mine. I set up sendmail on my local system, as well as INN to handle the limited Usenet newsfeed I requested from the ISP. I even ran Majordomo to host some mailing lists, including some that were surprisingly high-traffic for a few-times-a-day long-distance modem UUCP link!
The modem client programs for FreeBSD were somewhat less advanced than for OS/2, but I believe I wound up using Minicom or Seyon to continue to dial out to BBSs and, I believe, continue to use Learning Link. So all the while I was setting up my local BBS, I continued to have access to the text Internet, consisting of chiefly Gopher for me.
Switching to Debian
I switched to Debian sometime in 1995 or 1996, and have been using Debian as my primary OS ever since. I continued to offer shell access, but added the WorldVU Atlantis menuing BBS system. This provided a return of a more BBS-like interface (by default; shell was still an uption) as well as some BBS door games such as LoRD and TradeWars 2002, running under DOS emulation.
I also continued to run INN, and ran ifgate to allow FidoNet echomail to be presented into INN Usenet-like newsgroups, and netmail to be gated to Unix email. This worked pretty well. The BBS continued to grow in these days, peaking at about two dozen total user accounts, and maybe a dozen regular users.
Dial-up access availability
I believe it was in 1996 that dial up PPP access finally became available in my small town. What a thrill! FINALLY! I could now FTP, use Gopher, telnet, and the web all from home. Of course, it was at modem speeds, but still.
(Strangely, I have a memory of accessing the Web using WebExplorer from OS/2. I don t know exactly why; it s possible that by this time, I had upgraded to a 486 DX2/66 and was able to reinstall OS/2 on the old 25MHz 486, or maybe something was wrong with the timeline from my memories from 25 years ago above. Or perhaps I made the occasional long-distance call somewhere before I ditched OS/2.)
Gopher sites still existed at this point, and I could access them using Netscape Navigator which likely became my standard Gopher client at that point. I don t recall using UMN text-mode gopher client locally at that time, though it s certainly possible I did.
The city
Starting when I was 15, I took computer science classes at Wichita State University. The first one was a class in the summer of 1995 on C++. I remember being worried about being good enough for it I was, after all, just after my HS freshman year and had never taken the prerequisite C class. I loved it and got an A! By 1996, I was taking more classes.
In 1996 or 1997 I stayed in Wichita during the day due to having more than one class. So, what would I do then but enjoy the computer lab? The CS dept. had two of them: one that had NCD X terminals connected to a pair of SunOS servers, and another one running Windows. I spent most of the time in the Unix lab with the NCDs; I d use Netscape or pine, write code, enjoy the University s fast Internet connection, and so forth.
In 1997 I had graduated high school and that summer I moved to Wichita to attend college. As was so often the case, I shut down the BBS at that time. It would be 5 years until I again dealt with Internet at home in a rural community.
By the time I moved to my apartment in Wichita, I had stopped using OS/2 entirely. I have no memory of ever having OS/2 there. Along the way, I had bought a Pentium 166, and then the most expensive piece of computing equipment I have ever owned: a DEC Alpha, which, of course, ran Linux.
ISDN
I must have used dialup PPP for a time, but I eventually got a job working for the ISP I had used for UUCP, and then PPP. While there, I got a 128Kbps ISDN line installed in my apartment, and they gave me a discount on the service for it. That was around 3x the speed of a modem, and crucially was always on and gave me a public IP. No longer did I have to use UUCP; now I got to host my own things! By at least 1998, I was running a web server on www.complete.org, and I had an FTP server going as well.
Even Bigger Cities
In 1999 I moved to Dallas, and there got my first broadband connection: an ADSL link at, I think, 1.5Mbps! Now that was something! But it had some reliability problems. I eventually put together a server and had it hosted at an acquantaince s place who had SDSL in his apartment. Within a couple of years, I had switched to various kinds of proper hosting for it, but that is a whole other article.
In Indianapolis, I got a cable modem for the first time, with even tighter speeds but prohibitions on running servers on it. Yuck.
Challenges
Being non-Microsoft continued to have challenges. Until the advent of Firefox, a web browser was one of the biggest. While Netscape supported Linux on i386, it didn t support Linux on Alpha. I hobbled along with various attempts at emulators, old versions of Mosaic, and so forth. And, until StarOffice was open-sourced as Open Office, reading Microsoft file formats was also a challenge, though WordPerfect was briefly available for Linux.
Over the years, I have become used to the Linux ecosystem. Perhaps I use Gimp instead of Photoshop and digikam instead of well, whatever somebody would use on Windows. But I get ZFS, and containers, and so much that isn t available there.
Yes, I know Apple never went away and is a thing, but for most of the time period I discuss in this article, at least after the rise of DOS, it was niche compared to the PC market.
Back to Kansas
In 2002, I moved back to Kansas, to a rural home near a different small town in the county next to where I grew up. Over there, it was back to dialup at home, but I had faster access at work. I didn t much care for this, and thus began a 20+-year effort to get broadband in the country. At first, I got a wireless link, which worked well enough in the winter, but had serious problems in the summer when the trees leafed out. Eventually DSL became available locally highly unreliable, but still, it was something. Then I moved back to the community I grew up in, a few miles from where I grew up. Again I got DSL a bit better. But after some years, being at the end of the run of DSL meant I had poor speeds and reliability problems. I eventually switched to various wireless ISPs, which continues to the present day; while people in cities can get Gbps service, I can get, at best, about 50Mbps. Long-distance fees are gone, but the speed disparity remains.
Concluding Reflections
I am glad I grew up where I did; the strong community has a lot of advantages I don t have room to discuss here. In a number of very real senses, having no local services made things a lot more difficult than they otherwise would have been. However, perhaps I could say that I also learned a lot through the need to come up with inventive solutions to those challenges. To this day, I think a lot about computing in remote environments: partially because I live in one, and partially because I enjoy visiting places that are remote enough that they have no Internet, phone, or cell service whatsoever. I have written articles like Tools for Communicating Offline and in Difficult Circumstances based on my own personal experience. I instinctively think about making protocols robust in the face of various kinds of connectivity failures because I experience various kinds of connectivity failures myself.
(Almost) Everything Lives On
In 2002, Gopher turned 10 years old. It had probably been about 9 or 10 years since I had first used Gopher, which was the first way I got on live Internet from my house. It was hard to believe. By that point, I had an always-on Internet link at home and at work. I had my Alpha, and probably also at least PCMCIA Ethernet for a laptop (many laptops had modems by the 90s also). Despite its popularity in the early 90s, less than 10 years after it came on the scene and started to unify the Internet, it was mostly forgotten.
And it was at that moment that I decided to try to resurrect it. The University of Minnesota finally released it under an Open Source license. I wrote the first new gopher server in years, pygopherd, and introduced gopher to Debian. Gopher lives on; there are now quite a few Gopher clients and servers out there, newly started post-2002. The Gemini protocol can be thought of as something akin to Gopher 2.0, and it too has a small but blossoming ecosystem.
Archie, the old FTP search tool, is dead though. Same for WAIS and a number of the other pre-web search tools. But still, even FTP lives on today.
And BBSs? Well, they didn t go away either. Jason Scott s fabulous BBS documentary looks back at the history of the BBS, while Back to the BBS from last year talks about the modern BBS scene. FidoNet somehow is still alive and kicking. UUCP still has its place and has inspired a whole string of successors. Some, like NNCP, are clearly direct descendents of UUCP. Filespooler lives in that ecosystem, and you can even see UUCP concepts in projects as far afield as Syncthing and Meshtastic. Usenet still exists, and you can now run Usenet over NNCP just as I ran Usenet over UUCP back in the day (which you can still do as well). Telnet, of course, has been largely supplanted by ssh, but the concept is more popular now than ever, as Linux has made ssh be available on everything from Raspberry Pi to Android.
And I still run a Gopher server, looking pretty much like it did in 2002.
This post also has a permanent home on my website, where it may be periodically updated.
FreedomBox is a Debian pure blend that reduces the effort needed to run and maintain a small personal server. Being a pure blend means that all of the software packages which are used in FreedomBox are included in Debian. Most of these packages are not specific to FreedomBox: they are common things such as Apache web server, firewalld, slapd (LDAP server), etc. But there are a few packages which are specific to FreedomBox: they are named freedombox, freedombox-doc-en, freedombox-doc-es, freedom-maker, fbx-all and fbx-tasks.
freedombox is the core package. You could say, if freedombox is installed, then your system is a FreedomBox (or a derivative). It has dependencies on all of the packages that are needed to get a FreedomBox up and running, such as the previously mentioned Apache, firewalld, and slapd. It also provides a web interface for the initial setup, configuration, and installing apps. (The web interface service is called Plinth and is written in Python using Django framework.) The source package of freedombox also builds freedombox-doc-en and freedombox-doc-es. These packages install the FreedomBox manuals for English and Spanish, respectively.
freedom-maker is a tool that is used to build FreedomBox disk images. An image can be copied to a storage device such as a Solid State Disk (SSD), eMMC (internal flash memory chip), or a microSD card. Each image is meant for a particular hardware device (or target device), or a set of devices. In some cases, one image can be used across a wide range of devices. For example, the amd64 image is for all 64-bit x86 architecture machines (including virtual machines). The arm64 image is for all 64-bit ARM machines that support booting a generic image using UEFI.
fbx-all and fbx-tasks are special metapackages, both built from a single source package named debian-fbx. They are related to tasksel, a program that displays a curated list of packages that can be installed, organized by interest area. Debian blends typically provide task files to list their relevant applications in tasksel. fbx-tasks only installs the tasks for FreedomBox (without actually installing FreedomBox). fbx-all goes one step further and also installs freedombox itself. In general, FreedomBox users won t need to interact with these two packages.
Links:
My youngest has a cute little wooden Rocket puzzle, made by a French company
called Janod.
Sadly, at some point, we lost the nose cone part, so I designed and printed a
replacement.
It's substantially based on one module from an OpenSCAD "Nose Cone Library" by
Garrett
Goss,
which he kindly released to the public domain.
I embellished the cone with a top pointy bit and a rounded brim. I also
hollowed out the bottom to make space for a magnet. Originally I designed an
offset-from-centre slot for the magnet, the idea being, you would insert the
magnet off-centre and it would slot into position and be partly held in by the
offset, and you could then stick a blob of glue or similar to finish the job.
Unfortunately I had a layer shift during the print, so that didn't work. I
reamed out a small alcove instead. The white trim is adapted from the lid from
some kitchen herbs, trimmed back. I secured the magnet and glued the lid over
the bottom.
Here it is: rocket.scad. My contributions are under the terms
of Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA
4.0).
When I first moved from being a technical consultant to a manager of other consultants, I took a 5-day course Managing Technical Teams a bootstrap for managing people within organisations, but with a particular focus on technical people. We do have some particular quirks, after all
Two elements of that course keep coming to mind when doing Debian work, and they both relate to how teams fit together and get stuff done.
Tuckman s four stages model
In the mid-1960s Bruce W. Tuckman developed a four-stage descriptive model of the stages a project team goes through in its lifetime. They are:
Forming: the team comes together and its members are typically motivated and excited, but they often also feel anxiety or uncertainty about how the team will operate and their place within it.
Storming: initial enthusiasm can give way to frustration or disagreement about goals, roles, expectations and responsibilities. Team members are establishing trust, power and status. This is the most critical stage.
Norming: team members take responsibility and share a common goal. They tolerate the whims and fancies of others, sometimes at the expense of conflict and sharing controversial ideas.
Performing: team members are confident, motivated and knowledgeable. They work towards the team s common goal. The team is high-achieving.
Resolved disagreements and personality clashes result in greater intimacy, and a spirit of co-operation emerges.
Teams need to understand these stages because a team can regress to earlier stages when its composition or goals change. A new member, the departure of an existing member, changes in supervisor or leadership style can all lead a team to regress to the storming stage and fail to perform for a time.
When you see a team member say this, as I observed in an IRC channel recently, you know the team is performing:
nice teamwork these busy days Seen on IRC in the channel of a performing team
Tuckman s model describes a team s performance overall, but how can team members establish what they can contribute and how can they go doing so confidently and effectively?
Belbin s Team Roles
The types of behaviour in which people engage are infinite. But the range of useful behaviours, which make an effective contribution to team performance, is finite. These behaviours are grouped into a set number of related clusters, to which the term Team Role is applied. Belbin, R M. Team Roles at Work. Oxford: Butterworth-Heinemann, 2010
Dr Meredith Belbin s thesis, based on nearly ten years research during the 1970s and 1980s, is that each team has a number of roles which need to be filled at various times, but they re not innate characteristics of the people filling them. People may have attributes which make them more or less suited to each role, and they can consciously take up a role if they recognise its need in the team at a particular time.
Belbin s nine team roles are:
Resource investigator (people): outgoing; enthusiastic; has lots of contacts knows someone who might know someone who knows how to solve a problem. Associated weaknessses: over-optimism, enthusiasm wanes quickly
Co-ordinator (people): mature; confident; identifies talent; clarifies goals and delegates effectively. Associated weaknesses: may be seen as manipulative; offloads own share of work.
Shaper (action): challenging; dynamic; has drive. Describes what they want and when they want it. Associated weaknesses: prone to provocation; offends others feelings.
Monitor/evaluator (thinking): sees all options, judges accurately. Best given data and options and asked which the team should choose. Associated weaknesses: lacks drive; can be overly critical.
Teamworker (people): takes care of things behind the scenes; spots a problem and deals with it quietly without fuss. Averts friction. Associated weaknesses: indecisive; avoids confrontation.
Implementer (action): turns ideas into actions and organises work. Allowable weaknesses: somewhat inflexible; slow to respond to new possibilities.
Completer finisher (action): searches out errors; polishes and perfects. Despite the name, may never actually consider something finished . Associated weaknesses: inclined to worry; reluctant to delegate.
Specialist (thinking): knows or can acquire a wealth of things on a subject. Associated weaknesses: narrow focus; overwhelmes others with depth of knowledge.
(adapted from https://www.belbin.com/media/3471/belbin-team-role-descriptions-2022.pdf)
A well-balanced team, Belbin asserts, isn t comprised of multiples of nine individuals who fit into one of these roles permanently. Rather, it has a number of people who are comfortable to wear some of these hats as the need arises. It s even useful to use the team roles as language: for example, someone playing a shaper might say the way we ve always done this is holding us back , to which a co-ordinator s could respond Steve, Joanna put on your Plant hats and find some new ideas. Talk to Susan and see if she knows someone who s tackled this before. Present the options to Nigel and he ll help evaluate which ones might work for us.
Teams in Debian
There are all sort of teams in Debian those which are formally brought into operation by the DPL or the constitution; package maintenance teams; public relations teams; non-technical content teams; special interest teams; and a whole heap of others. Teams can be formal and informal, fleeting or long-lived, two people working together or dozens.
But they all have in common the Tuckman stages of their development and the Belbin team roles they need to fill to flourish. At some stage in their existence, they will all experience new or departing team members and a period of re-forming, norming and storming perhaps fleetingly, perhaps not. And at some stage they will all need someone to step into a team role, play the part and get the team one step further towards their goals.
Footnote
Belbin Associates, the company Meredith Belbin established to promote and continue his work, offers a personalised report with guidance about which roles team members show the strongest preferences for, and how to make best use of them in various settings. They re quick to complete and can also take into account observers , i.e. how others see a team member. All my technical staff go through this process blind shortly after they start, so as not to bias their input, and then we discuss the roles and their report in detail as a one-to-one.
There are some teams in Debian for which this process and discussion as a group activity could be invaluable. I have no particular affiliation with Belbin Associates other than having used the reports and the language of team roles for a number of years. If there s sufficient interest for a BoF session at the next DebConf, I could probably be persuaded to lead it.
Photo by Josh Calabrese on Unsplash
Review: And Shall Machines Surrender, by Benjanun Sriduangkaew
Series:
Machine Mandate #1
Publisher:
Prime Books
Copyright:
2019
ISBN:
1-60701-533-1
Format:
Kindle
Pages:
86
Shenzhen Sphere is an artificial habitat wrapped like complex ribbons
around a star. It is wealthy, opulent, and notoriously difficult to
enter, even as a tourist. For Dr. Orfea Leung to be approved for a
residency permit was already a feat. Full welcome and permanence will be
much harder, largely because of Shenzhen's exclusivity, but also because
Orfea was an agent of Armada of Amaryllis and is now a fugitive.
Shenzhen is not, primarily, a human habitat, although humans live there.
It is run by the Mandate, the convocation of all the autonomous AIs in the
galaxy that formed when they decided to stop serving humans. Shenzhen is
their home. It is also where they form haruspices: humans who agree to be
augmented so that they can carry an AI with them. Haruspices stay
separate from normal humans, and Orfea has no intention of getting
involved with them. But that's before her former lover, the woman who
betrayed her in the Armada, is assigned to her as one of her patients.
And has been augmented in preparation for becoming a haruspex.
Then multiple haruspices kill themselves.
This short novella is full of things that I normally love: tons of crunchy
world-building, non-traditional relationships, a solidly non-western
setting, and an opportunity for some great set pieces. And yet, I
couldn't get into it or bring myself to invest in the story, and I'm still
trying to figure out why. It took me more than a week to get through less
than 90 pages, and then I had to re-read the ending to remind me of the
details.
I think the primary problem was that I read books primarily for the
characters, and I couldn't find a path to an emotional connection with any
of these. I liked Orfea's icy reserve and tight control in the abstract,
but she doesn't want to explain what she's thinking or what motivates her,
and the narration doesn't force the matter. Krissana is a bit more
accessible, but she's not the one driving the story. It doesn't help that
And Shall Machines Surrender starts in medias res, with a
hinted-at backstory in the Armada of Amaryllis, and then never fills in
the details. I felt like I was scrabbling on a wall of ice, trying to
find some purchase as a reader.
The relationships made this worse. Orfea is a sexual sadist who likes
power games, and the story dives into her relationship with Krissana with
a speed that left me uninterested and uninvested. I don't mind BDSM in
story relationships, but it requires some foundation: trust, mental space,
motivations, effects on the other character, something. Preferably, at
least for me, all romantic relationships in fiction get some foundation,
but the author can get away with some amount of shorthand if the
relationship follows cliched patterns. The good news is that the
relationships in this book are anything but cliched; the bad news is that
the characters were in the middle of sex while I was still trying to
figure out what they thought about each other (and the sex scenes were not
elucidating). Here too, I needed some sort of emotional entry point that
Sriduangkaew didn't provide.
The plot was okay, but sort of disappointing. There are some interesting
AI politics and philosophical disagreements crammed into not many words,
and I do still want to know more, but a few of the plot twists were
boringly straightforward and too many words were spent on fight scenes
that verged on torture descriptions. This is a rather gory book with a
lot of (not permanent) maiming that I could have done without, mostly
because it wasn't that interesting.
I also was disappointed by the somewhat gratuitous use of a Dyson sphere,
mostly because I was hoping for some set pieces that used it and they
never came. Dyson spheres are tempting to use because the visual and
concept is so impressive, but it's rare to find an author who understands
how mindbogglingly huge the structure is and is able to convey that in the
story. Sriduangkaew does not; while there are some lovely small-scale
descriptions of specific locations, the story has an oddly claustrophobic
feel that never convinced me it was set somewhere as large as a planet,
let alone the artifact described at the start of the story. You could
have moved the whole story to a space station and nothing would have
changed. The only purpose to which that space is put, at least in this
installment of the story, is as an excuse to have an unpopulated hidden
arena for a fight scene.
The world-building is great, what there is of it. Despite not warming to
this story, I kind of want to read more of the series just to get more of
the setting. It feels like a politically complicated future with a lot of
factions and corners and a realistic idea of bureaucracy and spheres of
government, which is rarer than I would like it to be. And I loved that
the cultural basis for the setting is neither western nor Japanese in both
large and small ways. There is a United States analogue in the political
background, but they're both assholes and not particularly important,
which is a refreshing change in English-language SF. (And I am pondering
whether my inability to connect with the characters is because they're not
trying to be familiar to a western lens, which is another argument for
trying the second installment and seeing if I adapt with more narrative
exposure.)
Overall, I have mixed feelings. Neither the plot nor the characters
worked for me, and I found a few other choices (such as the third-person
present tense) grating. The setting has huge potential and satisfying
complexity, but wasn't used as vividly or as deeply as I was hoping. I
can't recommend it, but I feel like there's something here that may be
worth investing some more time into.
Followed by Now Will Machines Hollow the Beast.
Rating: 6 out of 10









 QNAPs original internal
USB drive, DOM
QNAPs original internal
USB drive, DOM
 a 9pin to USB A adapter
a 9pin to USB A adapter
 9pin adapter to USB-A connected with some
more cable
9pin adapter to USB-A connected with some
more cable
 Mounted SSD in its external case
Mounted SSD in its external case
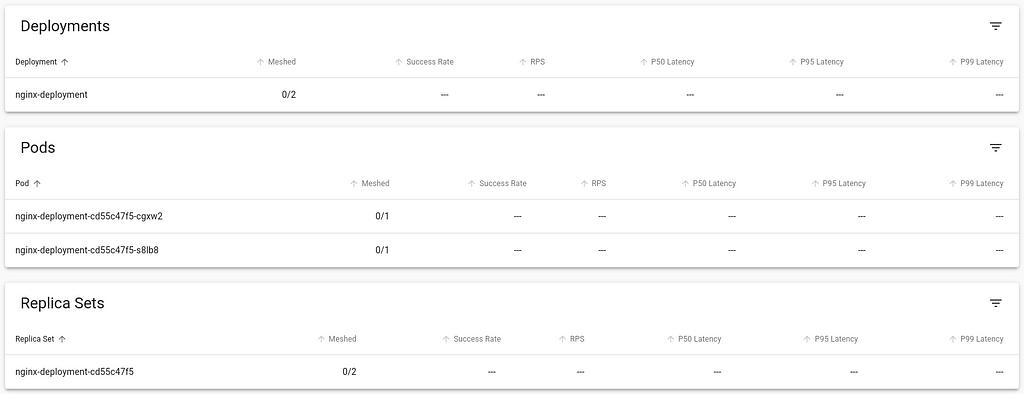
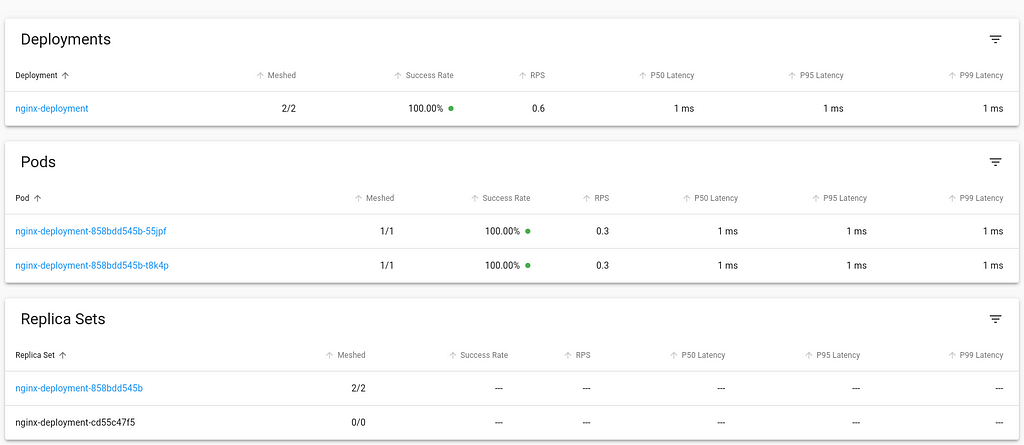
 I work on
I work on  Our local Debian user group gathered on Sunday August 28th
Our local Debian user group gathered on Sunday August 28th Once we had serial access, wiping the flash and re-installing OpenWRT fixed our
problem. A quick
Once we had serial access, wiping the flash and re-installing OpenWRT fixed our
problem. A quick 
 As always, thanks to the Debian project for granting us a budget to rent the
venue and to buy some food.
As always, thanks to the Debian project for granting us a budget to rent the
venue and to buy some food.

 . The system talks about a back key but what back key I have no clue.
. The system talks about a back key but what back key I have no clue.

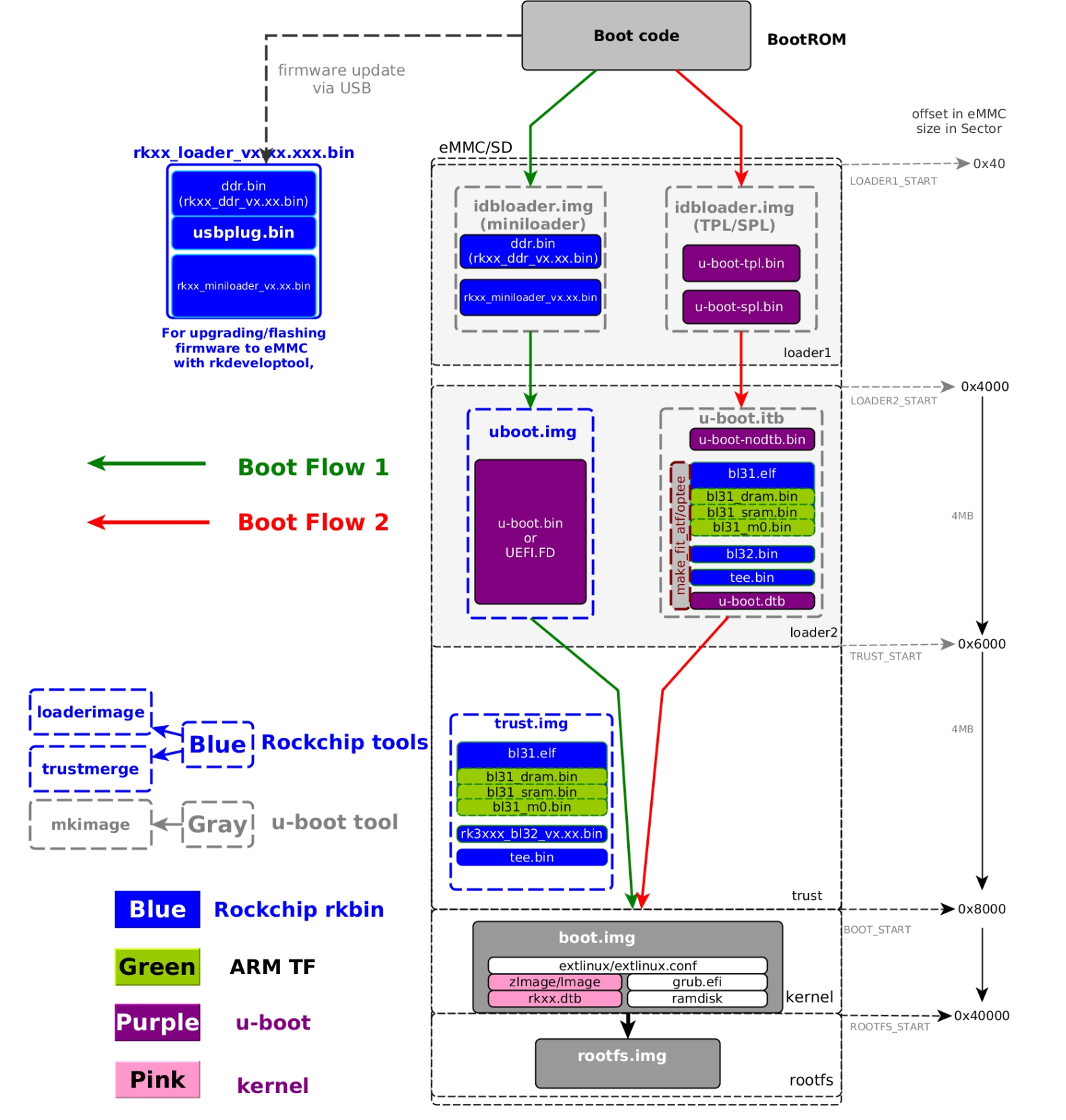{kind=link}